使用SQL Server Profiler追踪Power BI Desktop刷新问题
分类: PowerBI ◆ 标签: #大数据 #BI #数据分析 ◆ 发布于: 2025-02-21 21:06:54

Power BI Desktop报表使用Azure Databricks作为数据源,制作模型的时候使用Direct Query查询数据,如果在源数据中使用Decimal数据类型,有可能会丢失数据精度。
我们可以很容易重现这个问题,重现步骤如下:
在
Azure Databricks中创建一个数据源,创建的代码如下:CREATE DATABASE testdb; CREATE TABLE salaries ( Id Integer, Name varchar(50), Salary decimal(18, 5) ); INSERT INTO salaries (Id, Name, Salary) values (1, 'Tony', 9000.4466); INSERT INTO salaries (Id, Name, Salary) values (2, 'Mike', 7000.6521); INSERT INTO salaries (Id, Name, Salary) values (3, 'Bob', 5000.7890); INSERT INTO salaries (Id, Name, Salary) values (4, 'Sunny', 10000.66); INSERT INTO salaries (Id, Name, Salary) values (5, 'Jacky', 7000.4466); INSERT INTO salaries (Id, Name, Salary) values (6, 'Tom', 3000.4466); INSERT INTO salaries (Id, Name, Salary) values (7, 'Mindy', 8200.4466); INSERT INTO salaries (Id, Name, Salary) values (8, 'Brown', 9300.4466); INSERT INTO salaries (Id, Name, Salary) values (9, 'Mary', 9670.4466);启动
Power BI Desktop,创建一个空的报表,并且从Azure Databricks中导入表salaries, 导入完成后,选择model view,如下图:
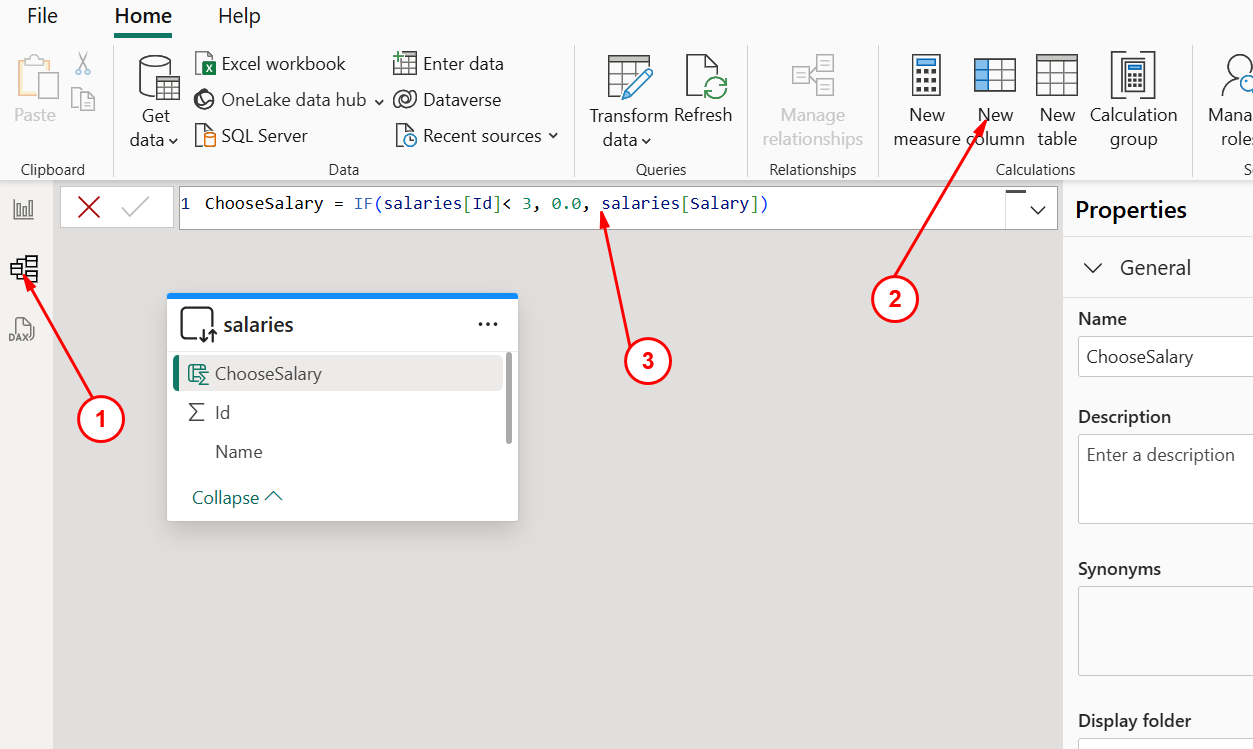
按照上述的步骤创建一个新列,新列的定义:
ChooseSalary = IF(salaries[Id]< 3, 0.0, salaries[Salary])创建新列之后,回到
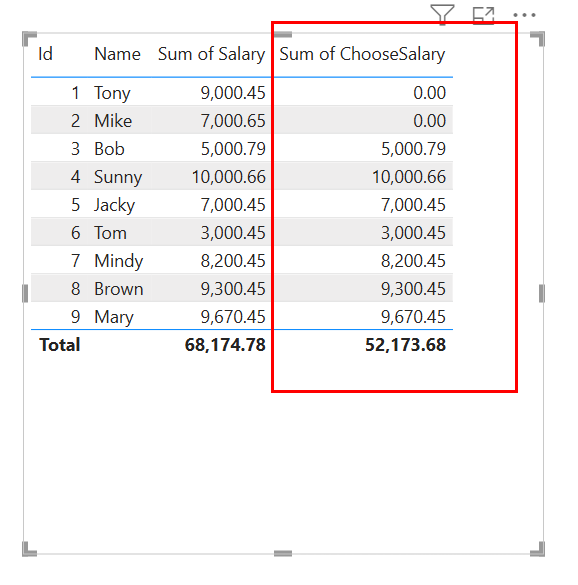
Report View, 在画布中添加Table, 然后选择Data的所有列,并且使用Sum函数对新建列ChooseSalary进行计算,如下图:
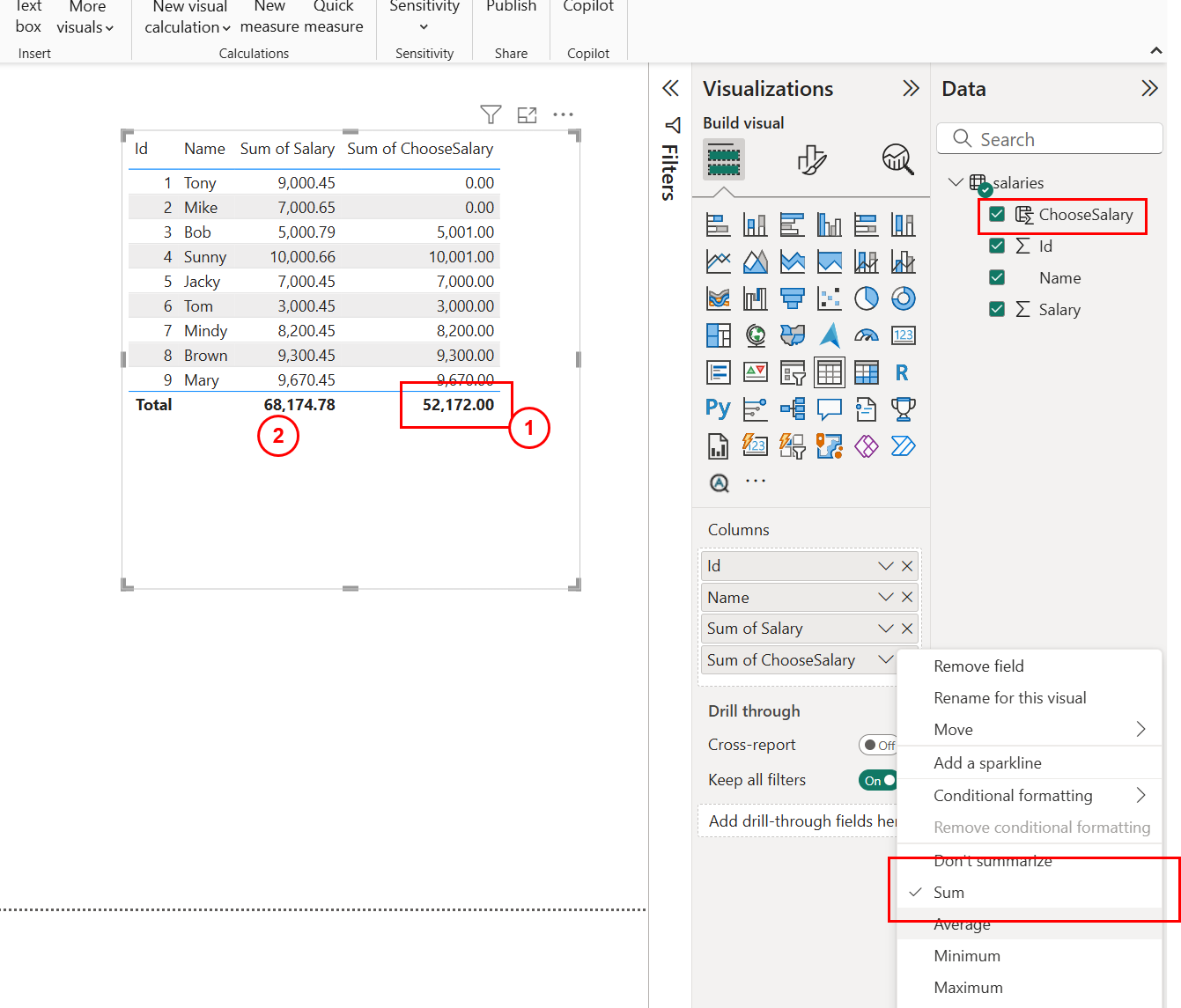
如上图红色的标记, 可以发现经过函数计算后,小数部分全部丢失,只有。如上图红色的标记
2, 可以发现经过函数Sum计算后,小数部分全部丢失,只有.00。
上述是重现问题的步骤。
如何分析和追踪类似的问题?
我们可以直接使用SQL Server Profiler来追踪和分析这类的问题,如果没有这个工具请下载并安装一下这个工具。
详细的步骤:
找到
Power BI Desktop的Mashup引擎在本地监听的端口。开启终端,并在终端运行命令:
tasklist /FI "imagename eq msmdsrv.exe" /FI "sessionname eq console" Image Name PID Session Name Session# Mem Usage ========================= ======== ================ =========== ============ msmdsrv.exe 19096 Console 5 108,104 K可以看到进程ID为
19096, 继续运行:netstat /ano | findstr "19096" TCP 127.0.0.1:61352 0.0.0.0:0 LISTENING 19096 TCP 127.0.0.1:61352 127.0.0.1:61359 ESTABLISHED 19096 TCP 127.0.0.1:61352 127.0.0.1:61361 ESTABLISHED 19096 TCP 127.0.0.1:61352 127.0.0.1:61371 ESTABLISHED 19096 TCP 127.0.0.1:61352 127.0.0.1:61420 ESTABLISHED 19096 TCP 127.0.0.1:61352 127.0.0.1:61426 ESTABLISHED 19096 TCP 127.0.0.1:61352 127.0.0.1:61591 ESTABLISHED 19096 TCP 127.0.0.1:61352 127.0.0.1:65446 ESTABLISHED 19096 TCP [::1]:61352 [::]:0 LISTENING 19096看第一行
TCP 127.0.0.1:61352 0.0.0.0:0 LISTENING 19096由此得知在本地的端口是61352启动
SQL Server Profiler, 使用菜单File -> New Trace, 如下图:
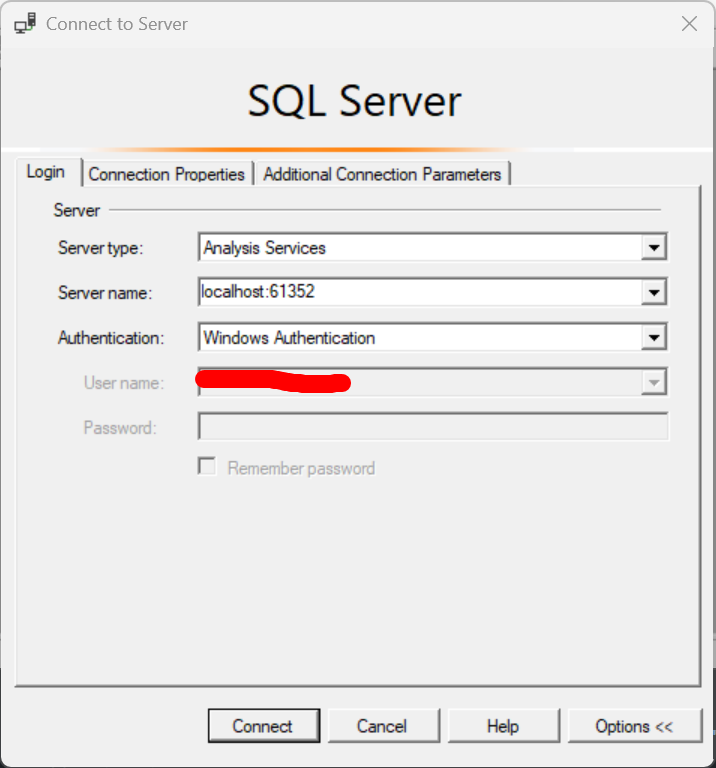
在新界面里选择Analysis Service,Service Name选择localhost:61352端口,认证使用windows 认证,如下图:
登录入之后,我们需要选择监听事件,如下图:
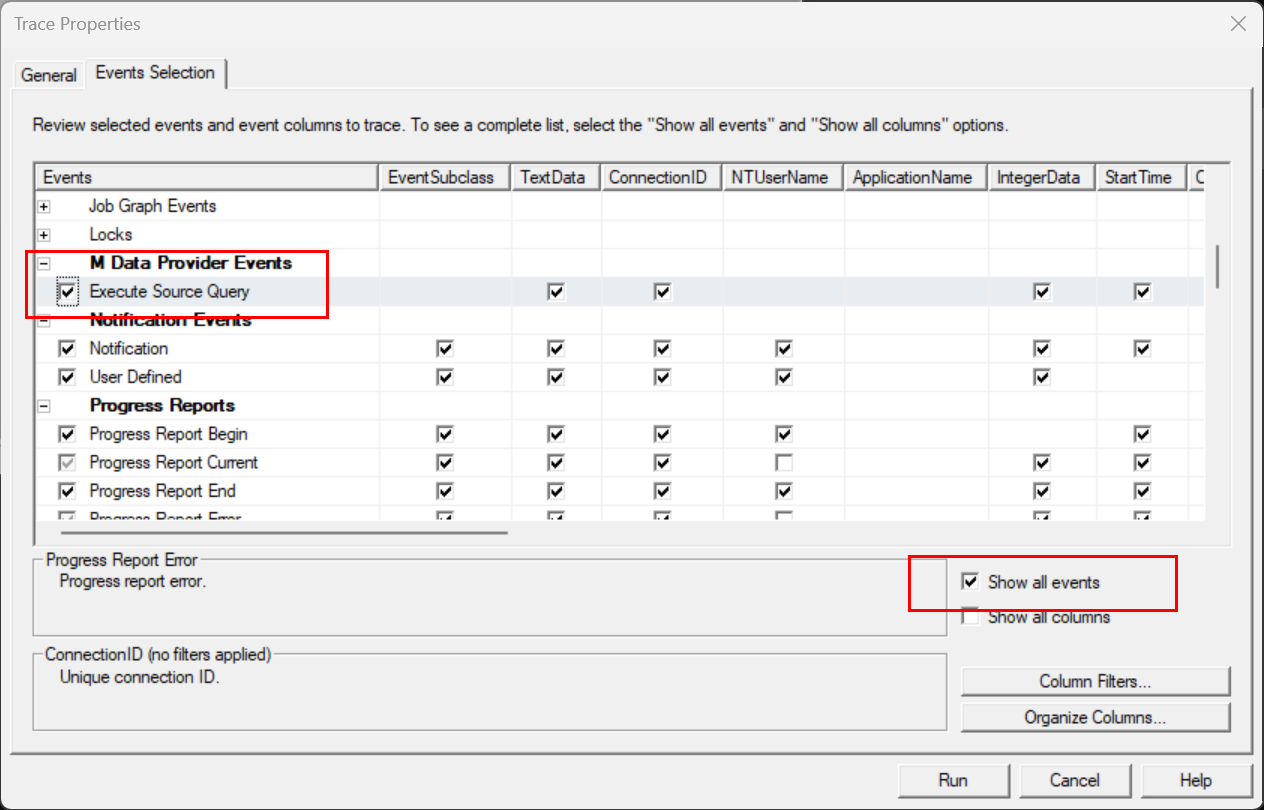
最后点击注意
由于我们这里的报表是采用的Direct Query模式, 因此所有的语句会送到数据源去运行,我们需要抓出送到数据源的语句是什么样子的,因此必须要记得要选择事件"M Data Provider Event -> Execute Source Query`, 如上图所示。run按钮开始抓取trace- 回到
Power BI Desktop刷新报表, 重现问题,观察SQL Server Profiler, 找到事件Execute Source Query, 然后拿到源查询语句之后,直接去Azure Databricks运行该语句,帮助我们判定具体是谁的问题: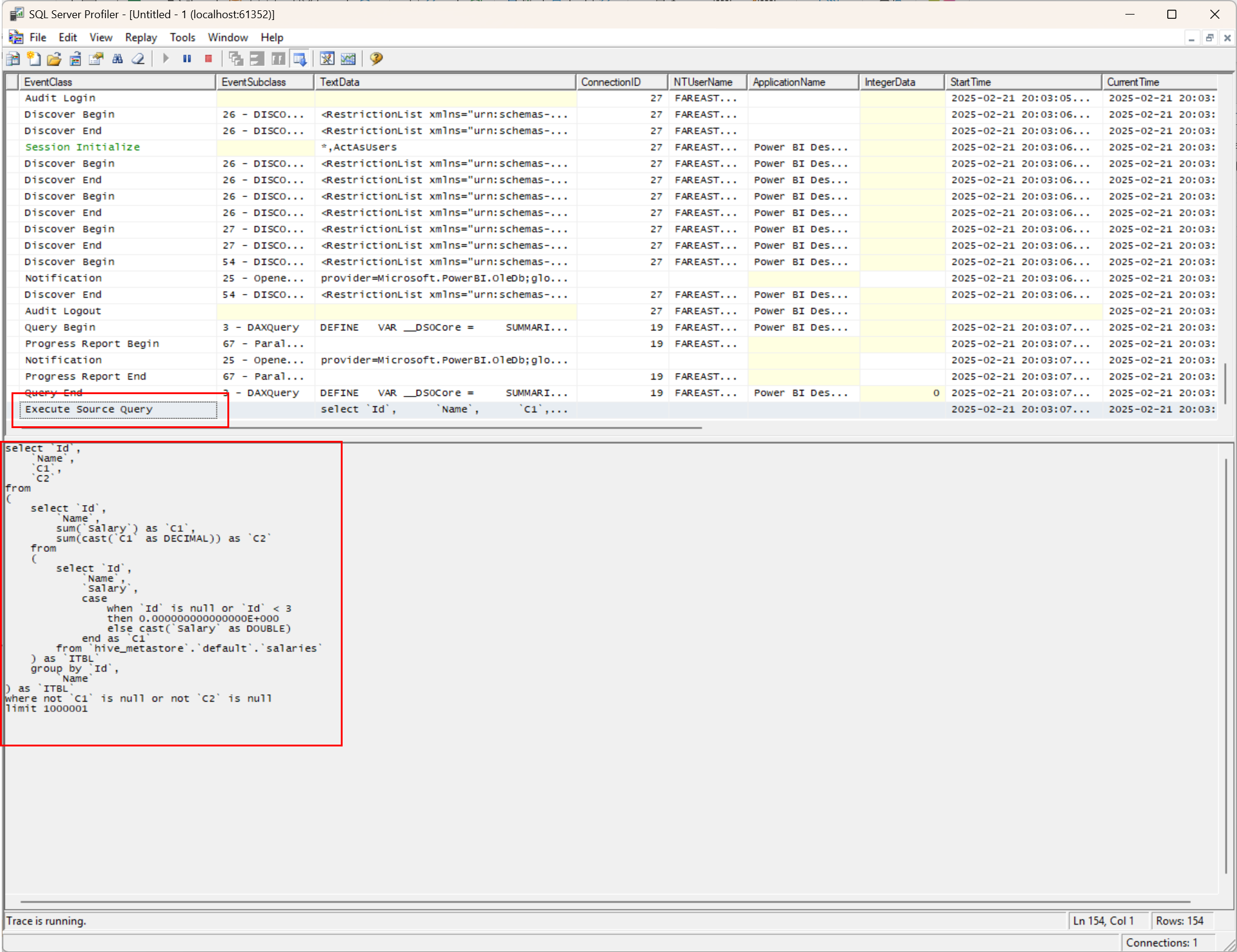
- 如上图所示,我们找到了事件
Execute Source Query, 并且抓到了实际在Azure Databricks运行的语句: select `Id`, `Name`, `C1`, `C2` from ( select `Id`, `Name`, sum(`Salary`) as `C1`, sum(cast(`C1` as DECIMAL)) as `C2` from ( select `Id`, `Name`, `Salary`, case when `Id` is null or `Id` < 3 then 0.000000000000000E+000 else cast(`Salary` as DOUBLE) end as `C1` from `hive_metastore`.`default`.`salaries` ) as `ITBL` group by `Id`, `Name` ) as `ITBL` where not `C1` is null or not `C2` is null limit 1000001分析
Azure Databricks的源语句,第一步先直接运行该语句:在Databricks中运行该语句发现也是所有的小数点都被丢掉了
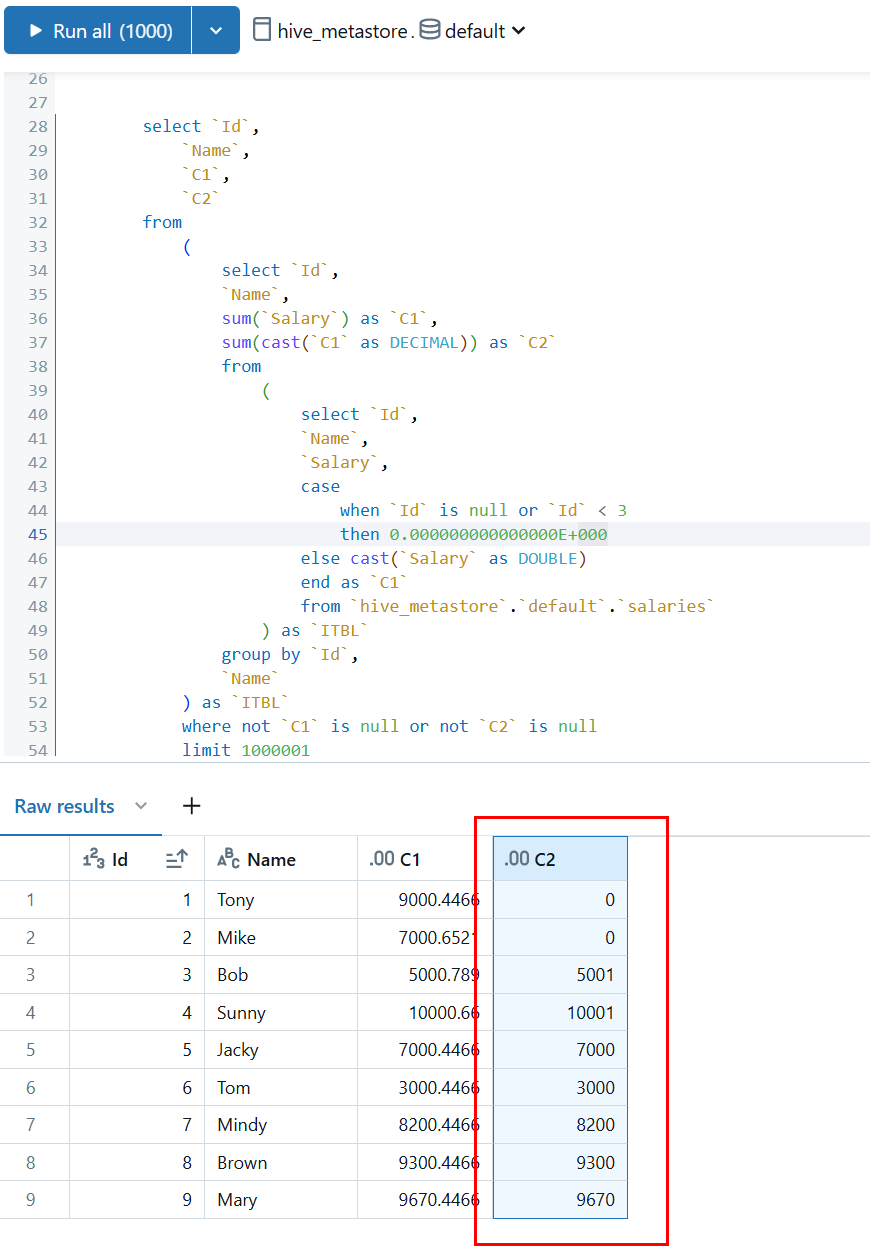
看来这个问题就是出在这个语句上,我们还需要进一步的分析为什么这个语句会掉精度, 为了解决这个问题,我们将上面的语句进行多次分解从里到外运行,具体的运行步骤如下:
select `Id`,
`Name`,
`Salary`,
case
when `Id` is null or `Id` < 3
then 0.000000000000000E+000
else cast(`Salary` as DOUBLE)
end as `C1`
from `hive_metastore`.`default`.`salaries`
这个时候注意到并没有丢掉小数点:
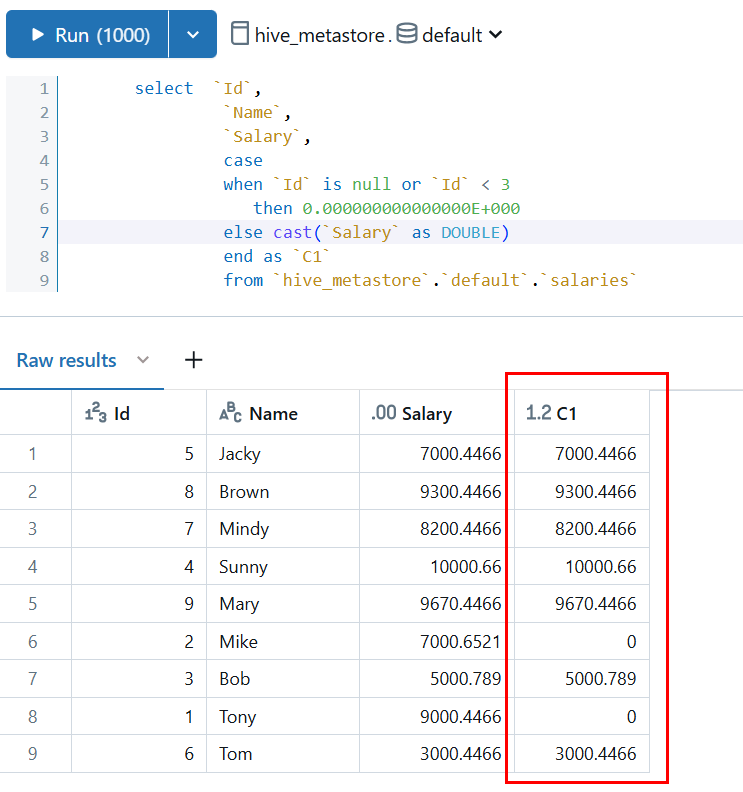
虽然没有丢失数据精度,但是需要注意的是这个查询里有一个cast语句,cast(Salary as DOUBLE), 将decimal数据类型向更宽的数据类型double 转换,因为double类型的取值范围更宽,不用担心会丢失精度。
继续运行语句:
select `Id`,
`Name`,
sum(`Salary`) as `C1`,
sum(cast(`C1` as DECIMAL)) as `C2`
from
(
select `Id`,
`Name`,
`Salary`,
case
when `Id` is null or `Id` < 3
then 0.000000000000000E+000
else cast(`Salary` as DOUBLE)
end as `C1`
from `hive_metastore`.`default`.`salaries`
) as `ITBL` group by `Id`,`Name`
运行该语句后,发现这个时候数据的精度就丢失了:
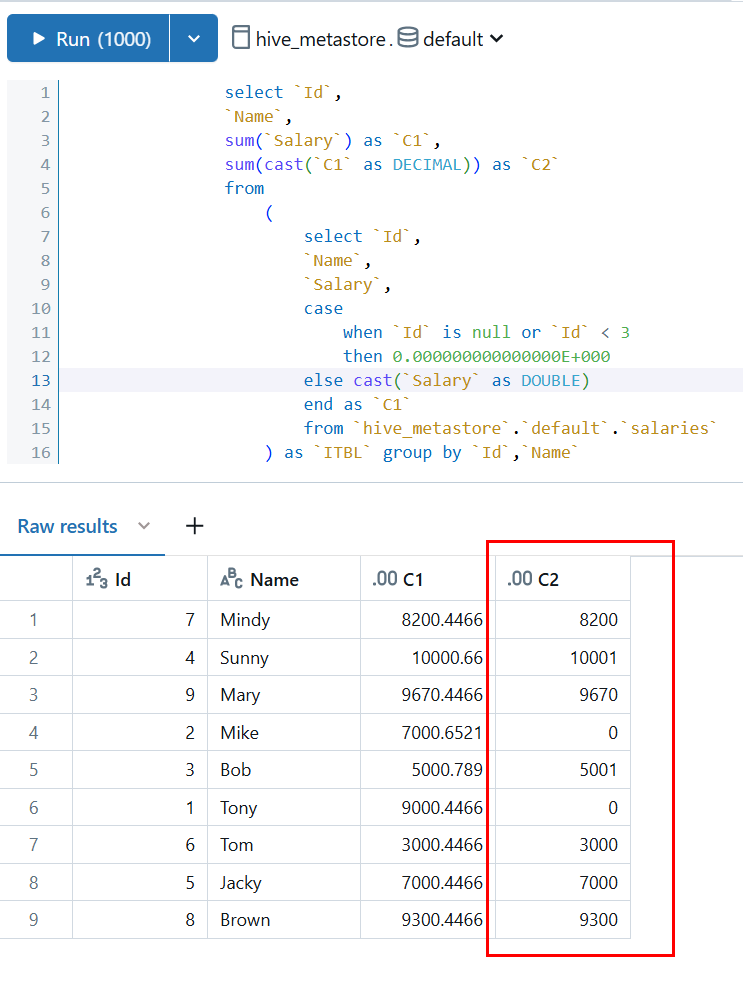
找到了问题发生的地点,只需要再次检查语句就可以发现,这个语句里最有可能丢失精度的地方就是cast(C1 as DECIMAL), 为什么是这个语句?因为内嵌的语句的类型是什么?是double, 所以C1 的类型应该是double, 它是一个更宽的数据类型,将double强制转换为decimal, 是绝对有机会丢失精度的。但是为什么全部丢得这么整齐?
这个时候需要检查一下数据类型
Decimal的基本定义,打开文档:https://learn.microsoft.com/en-us/azure/databricks/sql/language-manual/data-types/decimal-type, 可以发现文中有明确的定义:Syntax
{ DECIMAL | DEC | NUMERIC } [ ( p [ , s ] ) ]
p: Optional maximum precision (total number of digits) of the number between 1 and 38. The default is 10. s: Optional scale of the number between 0 and p. The number of digits to the right of the decimal point. The default is 0.在这个类型的定义时候,如果没有给出
precision(包括小数的所有位, 默认这个数字是10, 如果s(即小数位)没有给出,默认是0.到这里我们就总算找到原因了,是因为上述语句的类型转换中
cast(C1as DECIMAL)没有指定小数位,所以C1(decimal类型)小数位就是0, 这样所有的小数部分就被丢弃了。
如何判定是谁的问题?
通过事件M Data Provider Event 表明大概率是Databricks Connector的问题。
有没有缓解的方法
找到了原因就比较好办了,可以尝试重写之前定义类的语句,由:ChooseSalary = IF(salaries[Id]< 3, 0.0, salaries[Salary]) 改写为ChooseSalary = VALUE(IF(salaries[Id]< 3, 0.0, salaries[Salary])), 重新刷新,如下图:
为了理解为什么加了VALUE就可以缓解了,我们可以继续使用SQL Server Profiler追踪一下事件Execute Source Query, 找到源语句对比一下:
select `Id`,
`Name`,
`C1`,
`C2`
from
(
select `Id`,
`Name`,
sum(`Salary`) as `C1`,
sum(`C1`) as `C2`
from
(
select `Id`,
`Name`,
`Salary`,
cast({ fn left(cast((case
when `Id` is null or `Id` < 3
then 0.000000000000000E+000
else cast(`Salary` as DOUBLE)
end) as STRING), 4000) } as DOUBLE) as `C1`
from `hive_metastore`.`default`.`salaries`
) as `ITBL`
group by `Id`,
`Name`
) as `ITBL`
where not `C1` is null or not `C2` is null
limit 1000001
运行这个原句,对比一下,发现没有了cast double to decimal了。
不过本章的重点还是给大家介绍调试和追踪的思路和方法。