使用Azure Databricks通过JDBC读入大量数据异常处理(三)理解Databricks中的内存配置
分类: Azure Databricks ◆ 标签: #Azure #Databricks ◆ 发布于: 2023-06-18 19:46:44

在阅读这篇文章之前需要了解用户问题背景,您可以通过如下链接了解到:
我们之前一篇文章学习通过调整JDBC源配置提高并行度来缓解客户的问题,这是个比较好的解决方案,也是我们和Databricks的团队仔细讨论过的方案,是比较稳妥的做法。为了更好的理解客户的问题发生原因,我们还可以从Databricks的内存管理上入手,来讨论和学习如何从内存上缓解类似的问题。
Databricks是基于Spark的云平台,因此在架构上、内存管理上和传统的Spark会有区别,不过组件结构也是由driver和executor组成的,drvier和executor的分工也很明确:
driver的主要负责:
- 创建
SparkContext和SparkSession, 并运行用户代码中的main()方法 - 转换用户的代码到
Task - 创建
Lineage,Logical Plan,Physical Plan - 利用
Cluster Manager规划运行Task - 协调所有
executor以及task的执行。 - 以元数据的形式追踪所有的数据处理(原始数据被缓存在executor)
Executor主要负责:
- 运行
Task并将结果返回Driver - 缓存或者持久化数据到work node上。
我们本案例是在work node上爆出的OOM的问题,因此我们有必要详细的了解在executor上的内存的状态。
Executor的内存结构
内存管理我们能用得上的几个配置:
spark.executor.memory: 该配置用于配置executor的内存。spark.memory.fraction: 该配置项默认值是0.6, 该值用于配置Spark.executor.memory拥有的内存中多少内存用于保留内存,多少用于执行task的内存。例如0.6 表示百分之六十用于运行task.spark.memory.storageFraction: 该值在spark上默认是0.5, 表示用于分配执行task的内存一半用于executor memory, 另外一半用于storage memory, 关于这两部分的内存说明,我们后面再讨论。spark.memory.offHeap.enabled: 是否启用堆外内存spark.memory.offHeap.size: 设置堆外的内存大小
我们上面讨论了内存的几个配置项,我们下面看一下内存的结构:
executor实际就是启动一个JVM, 一个JVM仅仅是操作系统上的一个进程,因此spark.execute.memory没有启用堆外内存的情况下,他的结构如下图:
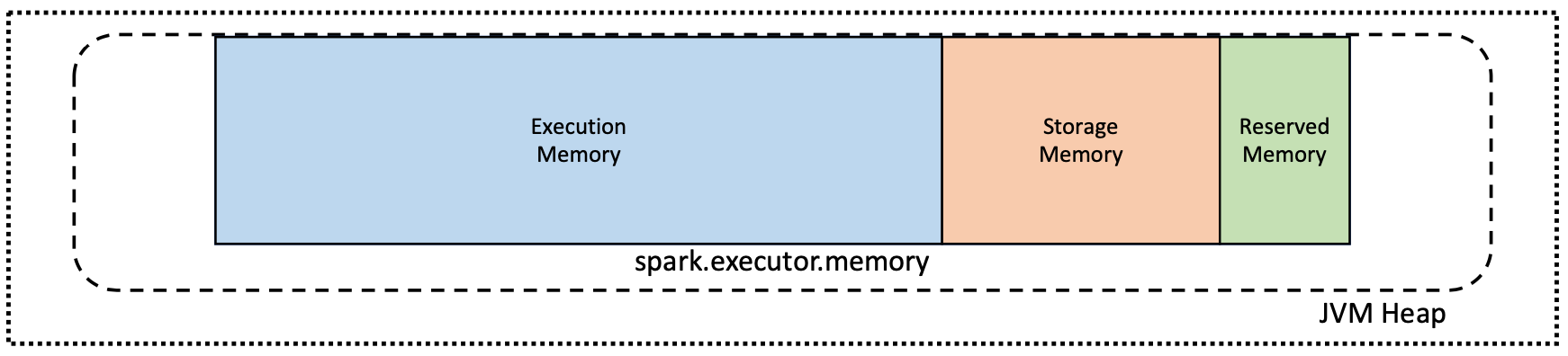
从图中可以看到spark.executor.memory由 三部分构成:
Execution Memory: 这部分内存用于执行shuffle,join,map等等动作时的数据暂留Storage Memory: 这部分内存主要用于缓存以及广播数据类型。Reserved Memory: 保留内存,这个部分内存虽然是保留内存,但是Spark的文档有明确的定义,这个部分内存可以用于防止OOM问题。
如果在启用了堆外内存,那么内存结果如下:
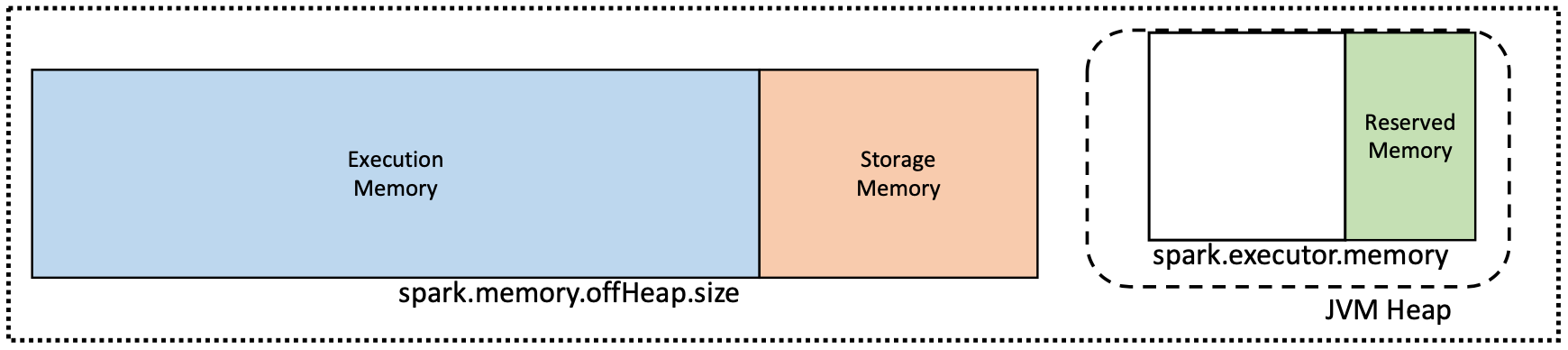
从这张图可以看到,如果启用了堆外内存,那么Executoion Memory和Storage Memory的内存就等于spark.memory.offhead.size
回到本案例中,客户一共是44G数据,330万行的数据,客户启动时并没有设置并行度,集群启动时为2个节点,这也就是说在最大的情况下,集群每个worker node会承担最大22个G的数据。
我们可以通过如下的数据来计算默认情况下spark.executor.memory的大小:
(all memory * 0.97 - 4800m) * 0.8 = spark.executor.memory
客户的worker node节点32个G:spark.executor.memory = (32 *1024* 0.97 – 4800m) * 0.8 = 21G
同时由于spark.memory.fraction= 0.6 默认情况下,那么实际上execute memory + storage memory = 12.6G
从客户错误的异常中可以看到应该是执行时内存OOM了。
那么通过我们对内存使用的分析,可以考虑如下两种方案:
- 增加更多的启动节点,经过测试该方案可行。
- 调整
spark.memory.fraction增加保留内存,虽然可以行,但是性能不好,原本只需要2个小时的任务,跑了3个半小时还多。