故障排查:Azure Machine Learning模型部署后多用户访问报429错误
分类: 故障排查 ◆ 标签: #Azure Machine Learning #机器学习 ◆ 发布于: 2023-08-07 22:21:35

Azure Machine Learning全面升级,从基于V1 SDK开始向V2 SDK升级,不过由于V2 SDK目前还是在Public Preview,没有正式发布,在使用V2 SDK的环境中经常会遇到各种奇奇怪怪的问题。
V2 SDK提供了很多新的特性,以及更合理的数据处理方式,在开始重现我们这个问题之前需要准备一下基本的工具和环境:
- 你需要一个
Azure订阅,您可以参考文章:https://www.azuredeveloper.cn/article/how-to-get-azure-account, 免费注册一个账号。 - 你需要创建一个
Azure Machine Learning的workspace。 - 安装
Azure Cli工具,您可以参考文章:https://www.azuredeveloper.cn/article/azure-tutorial-azure-cli-introduction, 安装好Azure Cli工具之后,通过命令az extension add --name ml, 安装Azure Machine learning的扩展。 - 下载
Azure Machine Learning的实例代码:https://github.com/Azure/azureml-examples
Azure Machine Learning模型部署支持real-time online endpoint, 同时支持两种方式的部署:
managed online endpoint: 部署在由Azure管理计算资源上。Kubernate: 目前仅仅提供由用户attach上去的k8s资源,同时之前的推理集群会被取消支持。
这两种计算资源对于Azure Machine learning模块的部署没有本质区别,唯一的区别在于管理资源的权限在谁的手上,因此他们有统一的部署和调整手段。
故障详细说明
模型训练完成之后,希望通过实时的终结点进行部署,然后用户可以通过该实时终结点提供的rest api接口向该终结点提交数据和请求,从而得到实时的推理结果。所谓的实时终结点不过是通过python Flask框架为基础搭建的Web服务,该服务中用一个默认命名为score.py的脚本作为主要的应用入口,向用户提供服务,该接口非常简单,要求提供两个方法:init - 执行初始化, run - 作为推理请求的入口方法,对于AML的终结点,建议接口专用,也就是AML的实时终结点避免放入其他的业务逻辑,就简简单单用于模型推理,而不应该将更多的业务逻辑带入到实时终结点中,毕竟实时终结点的架构是受限架构,如果需要更多的业务处理请求,完全可以使用其他技术来配合,例如将实时终结点部署到k8s或者aks专门的名称空间里,用于机器学习推理,在其他的名称空间里部署业务逻辑代码。
我们有发现在部署模型之后,如果由于模型性能或者推理的过程需要耗时较长,例如1秒以上的时候,如果使用测试工具,例如AB或者jmeter测试,只要并发线程在2个以上,就一直返回429错误。
问题重现
从github上下载azureml-examples代码之后:
cd azureml-examples\cli
az cloud set --name azurechinacloud
az login
az account set --subscription {Your 订阅ID}
同时这里的前提条件时你已经创建好了资源,例如:你的资源组是mlgroup, Azure Machine Learning的名称是testml, 那么我们在每一个az ml命令后都要指定--resource-group mlgroup --workspace-name testml。
我们进入到目录azureml-examples\cli之后,编辑代码:
notepad .\endpoints\online\model-1\onlinescoring\score.py
在文件头部载入time模块:
import time
更改方法def run(raw_data):
def run(raw_data): """ This function is called for every invocation of the endpoint to perform the actual scoring/prediction. In the example we extract the data from the json input and call the scikit-learn model's predict() method and return the result back """ logging.info("model 1: request received") data = json.loads(raw_data)["data"] data = numpy.array(data) result = model.predict(data) time.sleep(0.5) # 注意这里是模拟假设一次请求要超至少0.5秒。 logging.info("Request processed") return result.tolist()
然后保存该代码,回到命令行,使用如下的步骤创建实时终结点,并在该终结点上创建新的发布:
az ml online-endpoint create -f .\endpoints\online\managed\sample\endpoint.yml --name my-endpoint-5 --resource-group mlgroup --workspace-name testml
az ml online-deployment create -f .\endpoints\online\managed\sample\blue-deployment.yml --name blue --endpoint my-endpoint-5 --resource-group mlgroup --workspace-name testml
部署成功后,查看文件:
notepad.exe .\endpoints\online\managed\sample\sample-request.json
文件内容是可以放入rest api请求中的body:
{"data": [
[1,2,3,4,5,6,7,8,9,10],
[10,9,8,7,6,5,4,3,2,1]
]}
至此我们已经发布成功了我们的实时终结点,您可以登陆到Azure Portal找到该终结点的rest api相关的信息,如下图:
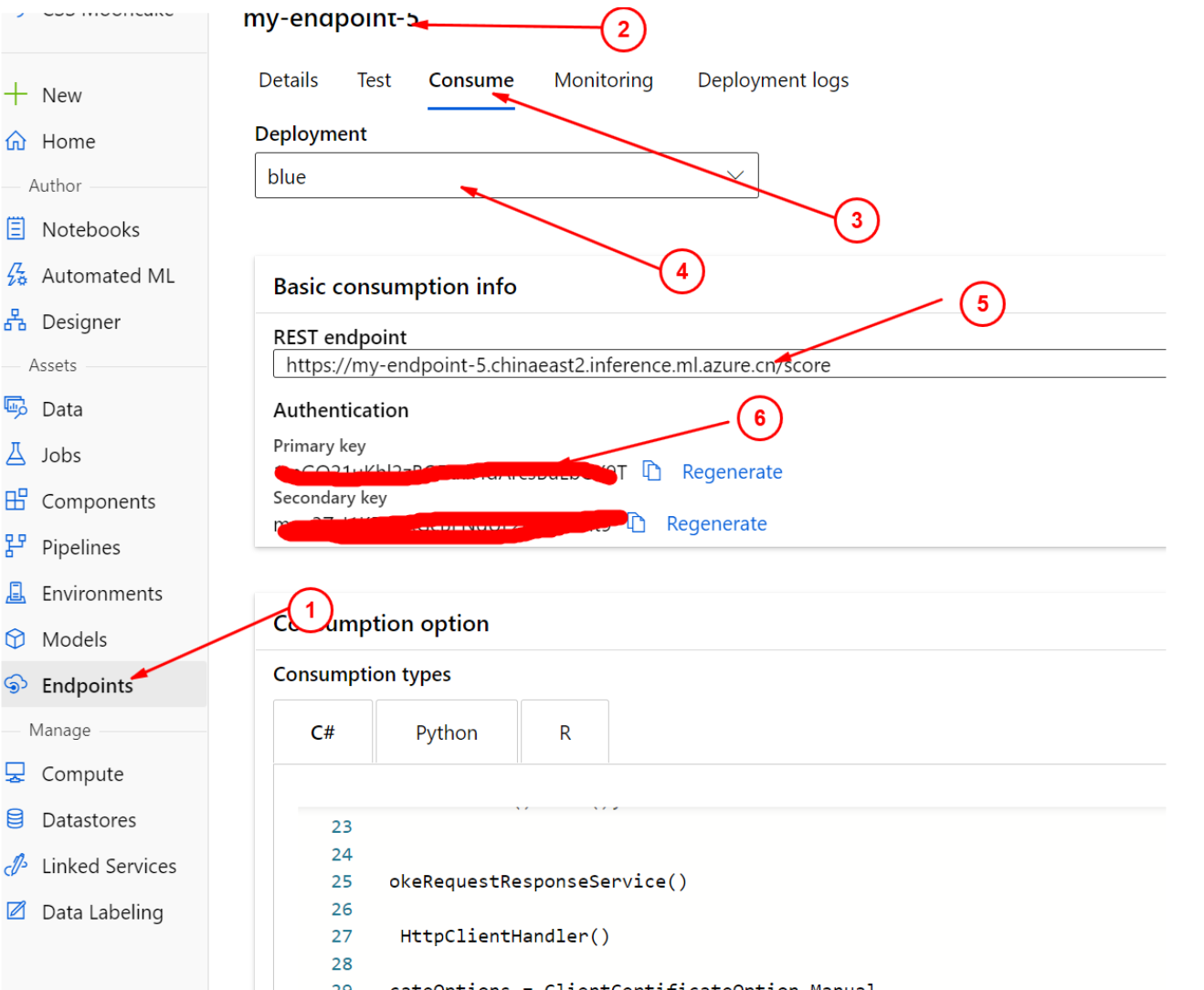
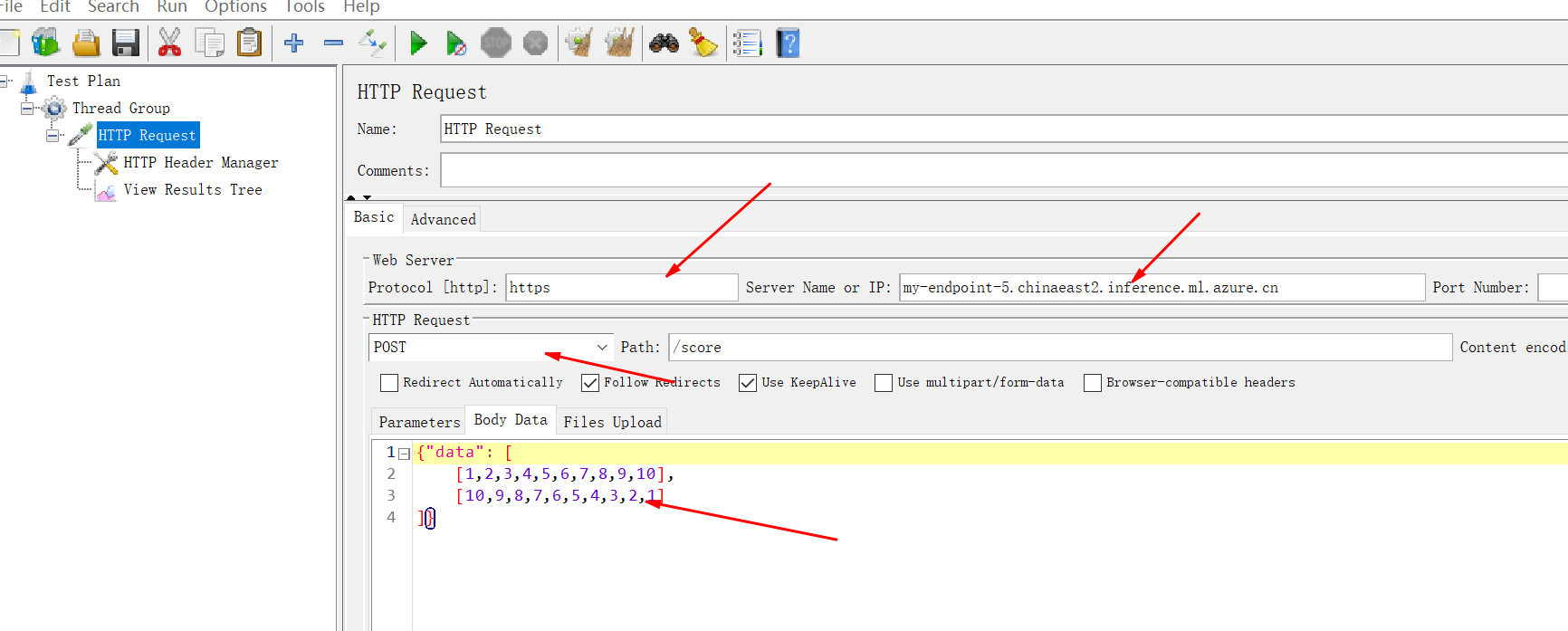
得到信息后如下图配置jmeter(对,你需要压测工具), 如下图的配置Jmeter测试工具:
设置请求的URL和请求额数据
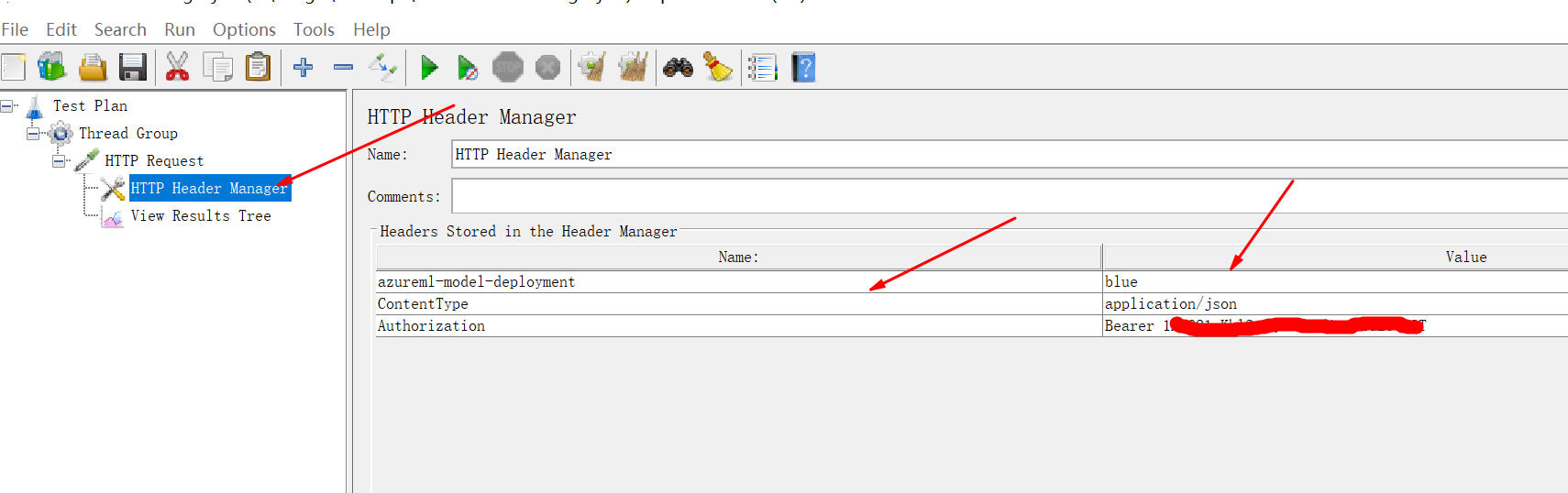
设置请求的头
如下是测试结果:
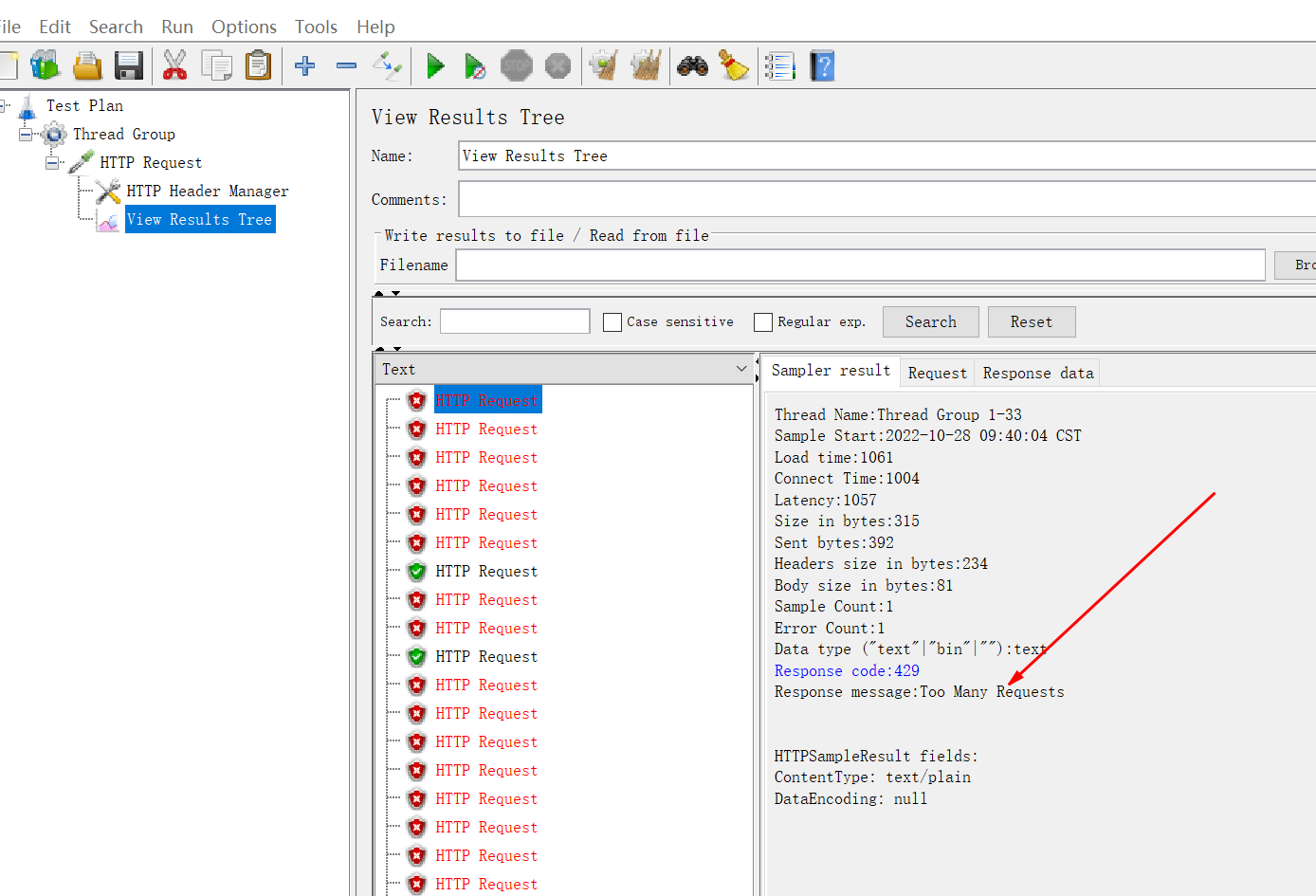
可以看到很多的429测试结果。
故障排除步骤和结果
之前就了解到online endpoint是基于python Flask架构的web终结点,猜测会有配置可以配置Flask框架的设置,仔细查询了Azureml-examples的实例,并没有发现相关的配置,继续从微软的设计出发,微软设计的产品易用性都是排在首位的,肯定会使用很多的概念隐藏复杂性,通过自己的设计来暴漏简易,易用的接口或者模板,回溯我们的步骤,就会发现AML将部署分成了两部,先创建实时终结点,然后在部署终结点,也就是说我们需要从终结点的配置和部署的配置入手。
从这个两个概念开始继续搜索微软的文档,发现:https://learn.microsoft.com/en-us/azure/machine-learning/reference-yaml-deployment-managed-online
也提醒我们在V2 SDK里大量使用了YAML进行配置,我们完全可以使用yaml schema来查询详细的定义:
https://learn.microsoft.com/en-us/azure/machine-learning/reference-yaml-overview
通过查询deployment的定义,我们可以发现:
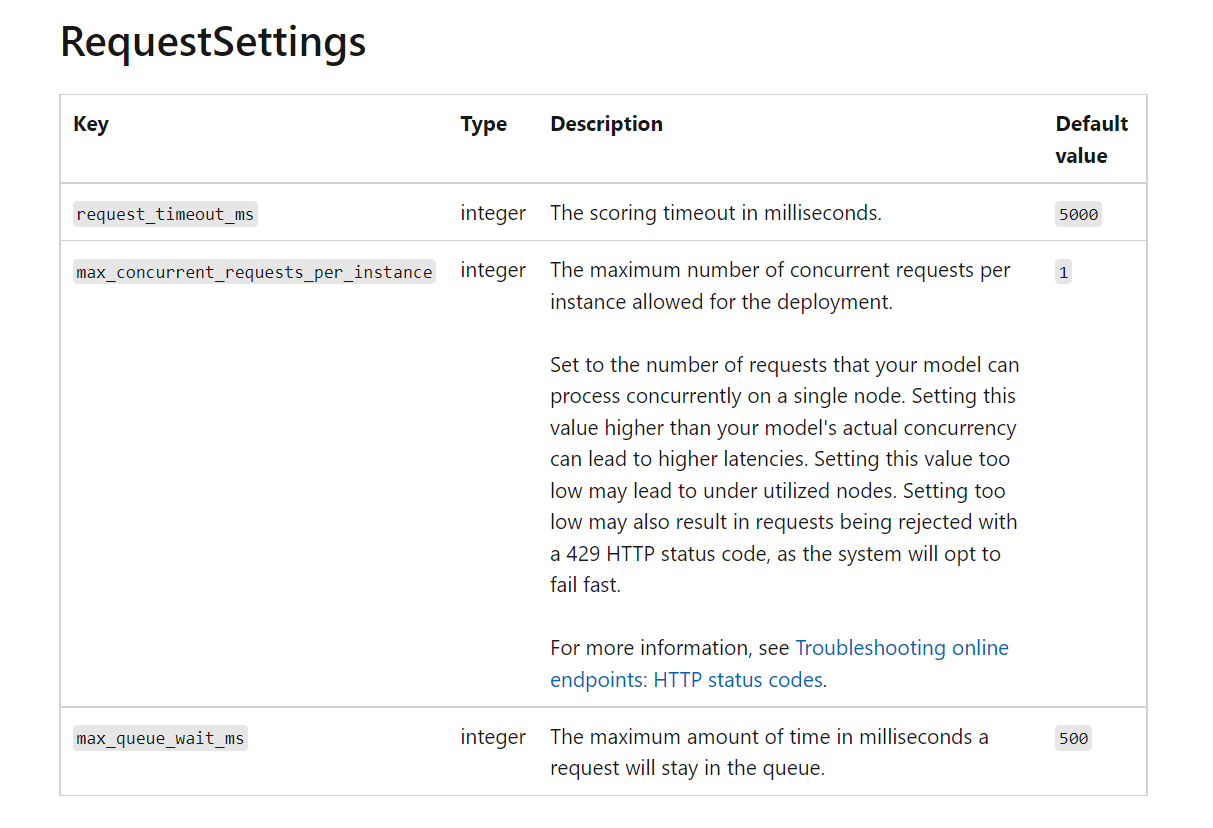
因此我们尝试编辑部署文件:
notepad.exe .\endpoints\online\managed\sample\blue-deployment.yml
更改内容如下:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: blue endpoint_name: my-endpoint model: path: ../../model-1/model/ code_configuration: code: ../../model-1/onlinescoring/ scoring_script: score.py environment: conda_file: ../../model-1/environment/conda.yml image: mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1 instance_type: Standard_DS2_v2 instance_count: 1 request_settings: max_concurrent_requests_per_instance: 50 max_queue_wait_ms: 5000 request_timeout_ms: 50000
重新部署之后,再次使用Jemeter测试,即可发现问题缓解.