使用Azure Databricks通过JDBC读入大量数据异常处理(二)优化JDBC源配置
分类: Azure Databricks ◆ 标签: #Azure #Databricks ◆ 发布于: 2023-06-18 19:43:36

我们之前的文章介绍了这个用户案例的背景,要学习本章需要认真了解一下背景,您可以通过如下的链接访问:<>
上篇结束时我们谈到过有两个解决方案可以缓解这个问题:
- 优化客户导入数据的代码,使用
JDBC数据源的配置项提升数据导入的并行度,避免发生Out Of Memory这样的问题。 - 优化集群的配置,调整
Spark运行过程中使用到内存环境, 避免发生Out OF Memory的问题。
我们本节来学习和讨论方案一,优化JDBC源配置。
我们可以使用如下的方式来缓解:
- 优化
pushdown query限制数据集,分批次导入数据集。 - 根据
JDBC数据源的配置选项,优化并行配置。 - 根据
JDBC数据源配置选项,配置fetchsize, 优化导入效率。
我们现在来学习这三个方案
限制数据集,分批次导入
该方案的很简单,既然一次导入330万, 44G数据容易出错,那么可以直接使用该表的主键,将330万数据分批次导入到delta table, 该方案很容易实行,很快就缓解了用户的问题,但是无法作为自动脚本来运行,必须手动多次导入。
原始的导入语句是:
val df = (spark.read.jdbc(url=jdbcUrl, table="<Table Name>", connectionProperties=connectionProperties))
我们任何可以使用pushdown query来进行优化, 将table名字换成具体的查询语句:
var pushdownquery = " (select * from <table name> where primarykey>= <value1> and primaryKey<= <Value2> ) <table name>_alias " val df = (spark.read.jdbc(url=jdbcUrl, table= pushdownquery, connectionProperties=connectionProperties))
同时在Spark使用如下的explian进行优化:
var pushdownquery = " (select * from <table name> where primarykey>= <value1> and primaryKey<= <Value2> ) <table name>_alias " val df = (spark.read.jdbc(url=jdbcUrl, table= pushdownquery, connectionProperties=connectionProperties)).explain(true)
或者也可以使用如下的形式进一步限定:
var pushdownquery = " (select * from <table name> ) <table name>_alias " val df = (spark.read.jdbc(url=jdbcUrl, table= pushdownquery, connectionProperties=connectionProperties)).select("<cloumn1>", "<cloumn1>", ...).where("<condition statement>").explain(true)
将pushdown query下发到数据库引擎之后,也可以在Spark侧查看结果,例如:
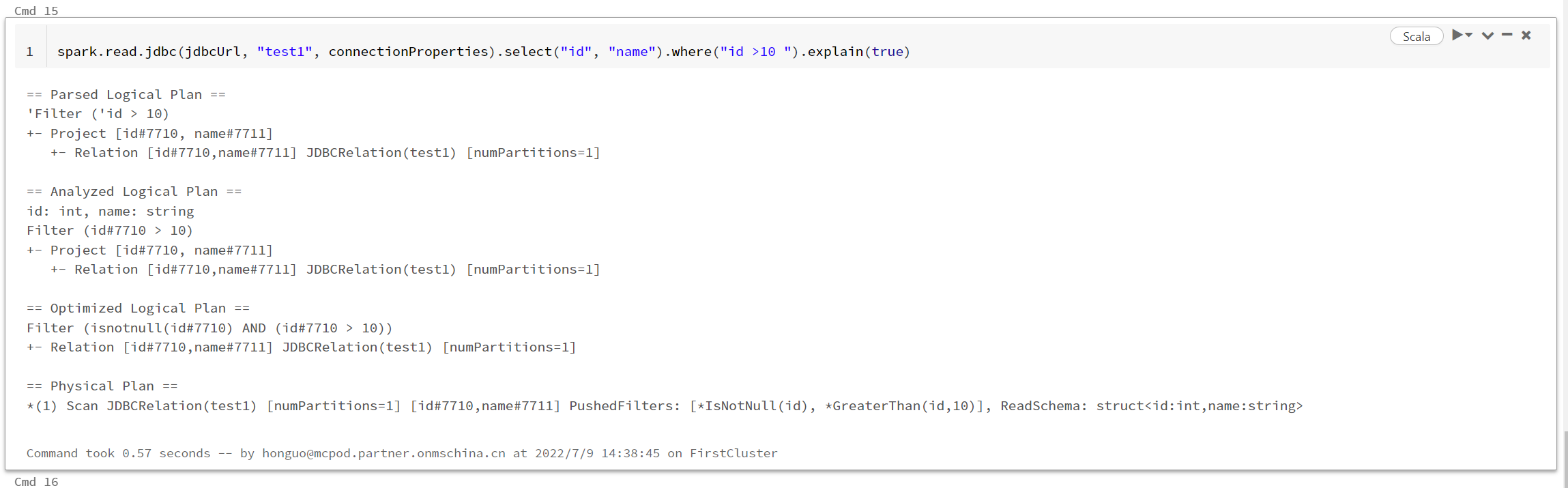
如果用户想自动执行就比较困难,或者要写更多的循环代码,例如使用for或者foreach, 将数据分拆成多个批次导入。
我们接下来看另外一个办法。
优化JDBC源配置项
Spark针对JDBC数据源有提供两个api, 用于并行执行:
- jdbc(url:String,table:String,partitionColumn:String,lowerBound:Long,upperBound:Long,numPartitions:Int, connectionProperties:Propertieys)
- jdbc(url:String,table:String,predicates:Array[String],...)
要注意的是运行jdbc还是会从表中或者是查询中拉取所有的数据,这里的参数只是为了确定在Spark这一侧的partion,以及每个partion需要处理的数据量。我们必须小心设计好每个参数,谨防数据倾斜的产生,如果设定了不合理的参数,可能会导致某些Partion处理输入的数量非常小,有些分区处理的数据量又非常巨大,产生了数据倾斜,这必然会导致性能问题。
参数:partitionColumn, lowerBound, upperBound, numPartitions
我们先来看第一个方法中提及的参数,如果您使用了这些参数中的一个,那么上述几个参数都要定义,否则就会出错。
partitionColumn: 这个参数定义了在Spark中会根据源表的哪个字段进行分区。numPartitions: 设定需要分区的个数,也就是我们的并行度。lowerBound,upperBound: 这两个参数比较难以理解,我们用一个例子来说明这个两个参数如何使用。
假如你有一个MySQL表,这个表里的数据有1000行(我们这里用1000行,仅仅是为了好演示), 你希望用JDBC数据源读入到Spark的delta表中, 同时为了提高并行度,你想使用5个分区,也就是并行度是5, 为了不发生数据倾斜,你希望这个5个分区里的数据都是均等的。由于我们现在知道你目前有1000行数据,为了均等,非常容易计算:1000 / 5 = 200, 也就是每一个分区要处理200行,这样就不会有数据倾斜,因为每个分区的行数都是一样的。问题是如何给lowerBound和upperBound赋值,才能使得每个分区正好处理200行呢?
记住一个公式: (uppwerBound - lowerBound) / numberParitions = 每个分区处理的数据数,我们这里就是行数。
(upperBound - lowerBound ) / 5 = 200, 按照这个推测就好了。那么 upperBound = 1000, lowerBound = 0, 是合适的赋值。
由此我们得到所有参数的赋值:
partitionColumn='id': 最好用于分区的就是表的主键,几乎是天然用于分区的列。lowerBound=0: 根据我们上述的值推测的。upperBound=1000: 根据我们的需求推测的numPartitions=5: 根据我们的数据总量我们选择的一个任意值。
这里有另外一个问题,numPartitions的值我们应该选择多少呢?
是否有什么标准让我们定义数据处理的并行度呢?
我们需要根据您的数据以及集群的情况来决定并行度,但是这里有一个经过验证的规则:就是单个分区处理的数据不要超过一个G。 那么如何根据这个规则来计算一个分区大约能处理多少行数呢? 也很简单,计算一下源数据库的一行数据大约占多少大小,然后用1G 去除以行数据的大小,就可以知道大约每个分区能够处理多少行,从而可以计算出多少个分区。
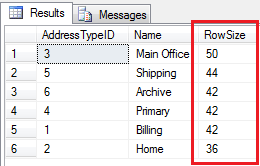
如何计算关系数据库一行数据的大小?这方法就太多了,自行百度或者谷歌一下,例如SQL Server计算一行数据大小:
-- Declaring variables declare @table nvarchar(128); declare @idcol nvarchar(128); declare @sql nvarchar(max); --initialize those two values set @table = '[Person].[AddressType]' set @idcol = 'AddressTypeID, Name' set @sql = 'select ' + @idcol + ' , (0' -- This select statement collects all columns of a table and calculate datalength select @sql = @sql + ' + isnull(datalength(' + name + '), 1)' from sys.columns where object_id = object_id(@table) set @sql = @sql + ') as RowSize from ' + @table + ' order by rowsize desc' -- Execute sql query exec (@sql)
结果如下:
理解Spark如何根据分区参数和数据库交互
假如我们没有使用上述并行度参数,那会发生什么呢?Spark使用单一的分区(没有并行度), 如果表一大就很容易导致OOM问题发生。那么我们使用了并行度,Spark会如何和数据库交互呢?
还是上述的例子,我们使用了参数:
partitionColumn='id'lowerBound=0upperBound=1000numPartitions=5
那么实际上在Spark这一侧每个分区上分别运行如下的SQL语句:
select * from <tableName> where <paritioncolumn> < 200 or <partionColumn> is null select * from <tableName> where <paritioncolumn> >= 200 and <partionColumn> < 400 select * from <tableName> where <paritioncolumn> >= 400 and <partionColumn> < 600 select * from <tableName> where <paritioncolumn> >= 600 and <partionColumn> < 800 select * from <tableName> where <paritioncolumn> >=800
我们可以归结为如下的公式:
stride, s= (u-l)/n **SELECT * FROM table WHERE partitionColumn < l+s or partitionColumn is null** SELECT * FROM table WHERE partitionColumn >= l+s AND <2s SELECT * FROM table WHERE partitionColumn >= l+2s AND <3s ... **SELECT * FROM table WHERE partitionColumn >= l+(n-1)s**
Tips: u = upperBound, l = lowerBound
这样我们就提高了并行度。
参数predicates:Array[String]
我们上述是结合多个参数进行并行度的设定,我们这里使用单一的参数predicates来设定并行度。
这个API非常直接,就是定义一个where cause的条件语句在数据这一侧限定多少数据需要处理。非常适合用于那些非数字型的分区字段使用,例如日期字段等等。这个就不用举例了。
可以参考文章:https://www.perceptivebits.com/increase-pysparks-jdbc-parallelism-through-predicates/
fetsize
这个参数仅仅是JDBC的statement语句定义的一个值,我们可以暂时忽略这个参数,因为每个驱动都有不同的定义,甚至会直接忽略这个参数。
好了,我们今天学习了如何从用户代码以及JDBC配置侧缓解这个问题,我们明天继续从集群内存配置和管理上如何来缓解这个问题。