无需代码经验的机器学习第二天 - 使用设计器训练模型
分类: Azure机器学习 ◆ 标签: #Azure #人工智能 #机器学习 #设计器 #JupyterBook ◆ 发布于: 2023-06-12 17:25:33

我们在前一天学习了使用Azure Machine Learning Studio的Auto ML任务创建Azure Auto ML模型训练,在这个过程中,我们无需任何代码经验,只需要简单的界面点击就可以训练出需要的模型,虽然Azure AutoML非常容易使用,但是我们也需要注意到Azure Auto ML的限制,也就是Azure Auto ML仅仅使用三种模型的训练:分类模型, 回归模型, 基于时序预测模型, 如果你的应用场景超出了这三种模型仅仅依靠Auto ML是无法满足实际的需求的, 除了直接使用Azure Auto ML任务你还可以使用Azure Machine Learning Studio推出的设计器来创建自己的AML pipeline来完成机器学习的其他模型的训练,同样使用这个工具你仍然无需任何的代码经验,接下来在本节,我们将使用一个例子使用设计器来训练一个回归模型,借此抛砖引玉。
开始之前
在开始本章之前,你需要:
- 一个Azure订阅
- 创建一个
Azure Machine Learning的workspace - 启动
Azure Machine Learning studio
Azure Machine Learning Pipeline
我们在学习微软的技术的时候,有个概念叫管道(Pipeline), 在微软的很多产品中都有提及,例如我们在学习ASP.net core这个框架的时候使用过pipeline的概念,在使用Azure的Data Factory的时候也用过pipeline的概念,如果你熟悉Azure Devops那么也会提到pipeline的概念,可见微软的技术和工具对于pipeline这个概念和设计方式是非常的请求独钟,就像大家在学习面向对象设计以及Java的时候,Java中提及最多的一个概念就是设计模式, 方法论是对于技术的一个总结和升华,建议学习技术的朋友应该更认真的思考这个问题。
微软技术中使用pipeline这个概念来表示很多业务中的一个可以复用的流程,我们的designer是为无代码设计的,虽然不需要编写代码,但是在处理一项业务的时候,任然需要处理各种业务逻辑,需要判断,循环,跳转等等标准的流程,同时我们写代码时需要用代码的形式将所有的逻辑描述出来,并且以类,函数等各种形式进行复用,那么pipeline就是对代码的更高一层次的复用,使用pipeline来设计业务中的各种逻辑,并且保存这个pipeline, 在需要的时候再调用该pipeline, 这就是它的主要租用。
Azure Machine Learning Designer 使用Azure Machine Learning Pipeline来达到这个效果,实际上designer大部分的工作都在设计pipeline。
训练模型
通过前面的铺垫,相信大家已经对于基本的概念有了一些了解,同时如果还不了解Azure机器学习的基本概念和基本工具,建议可以参考我们前面的文章,包括使用Python SDK以及jupyter来对于机器学习的基本概念如何和Azure进行集成有一个基本的了解,然后再来使用可视化的工具,会更加事半功倍。
创建Pipeline
进入stuido之后,选择左侧的菜单栏,然后找到设计器, 选择设计器之后,即可打开设计器的界面,如下图:
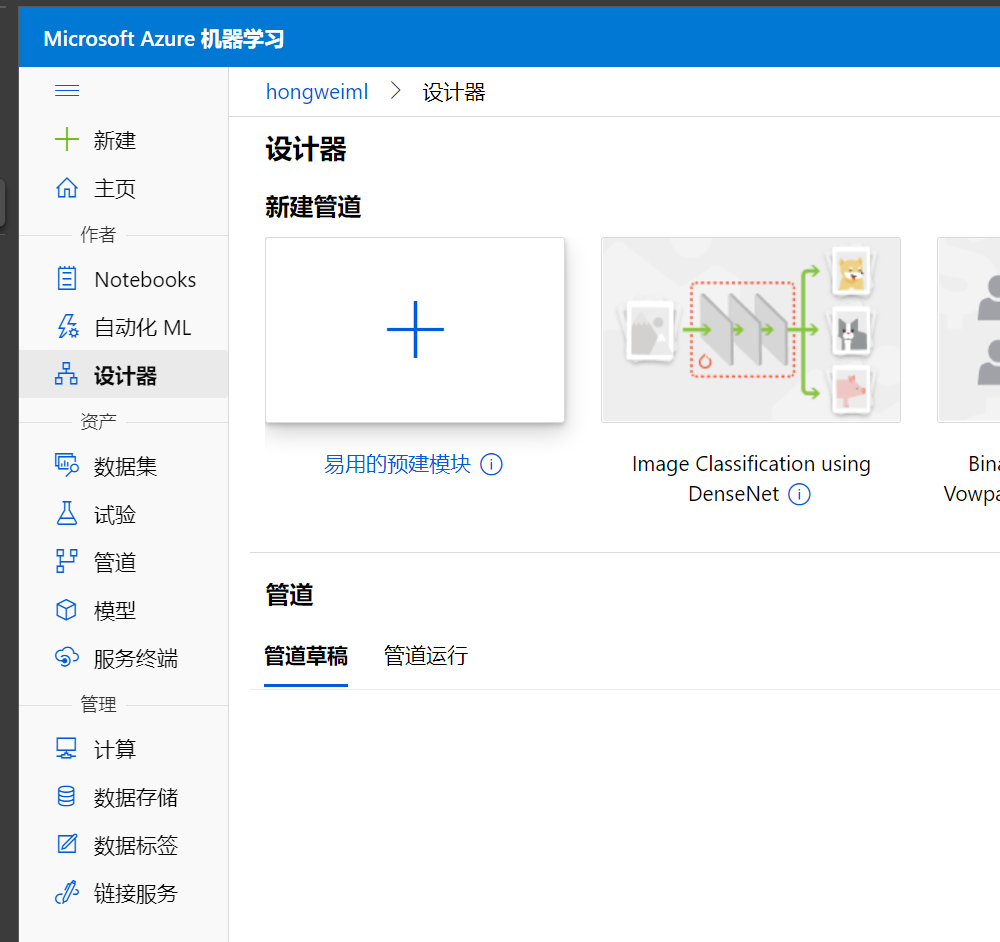
点击那个大大的'+' 号之后,即创建了一个新的pipeline, 点击标题栏,将pipeline的标题改为汽车价格预测, 同时点击旁边的设置按钮,可以打开该pipeline的设置界面:
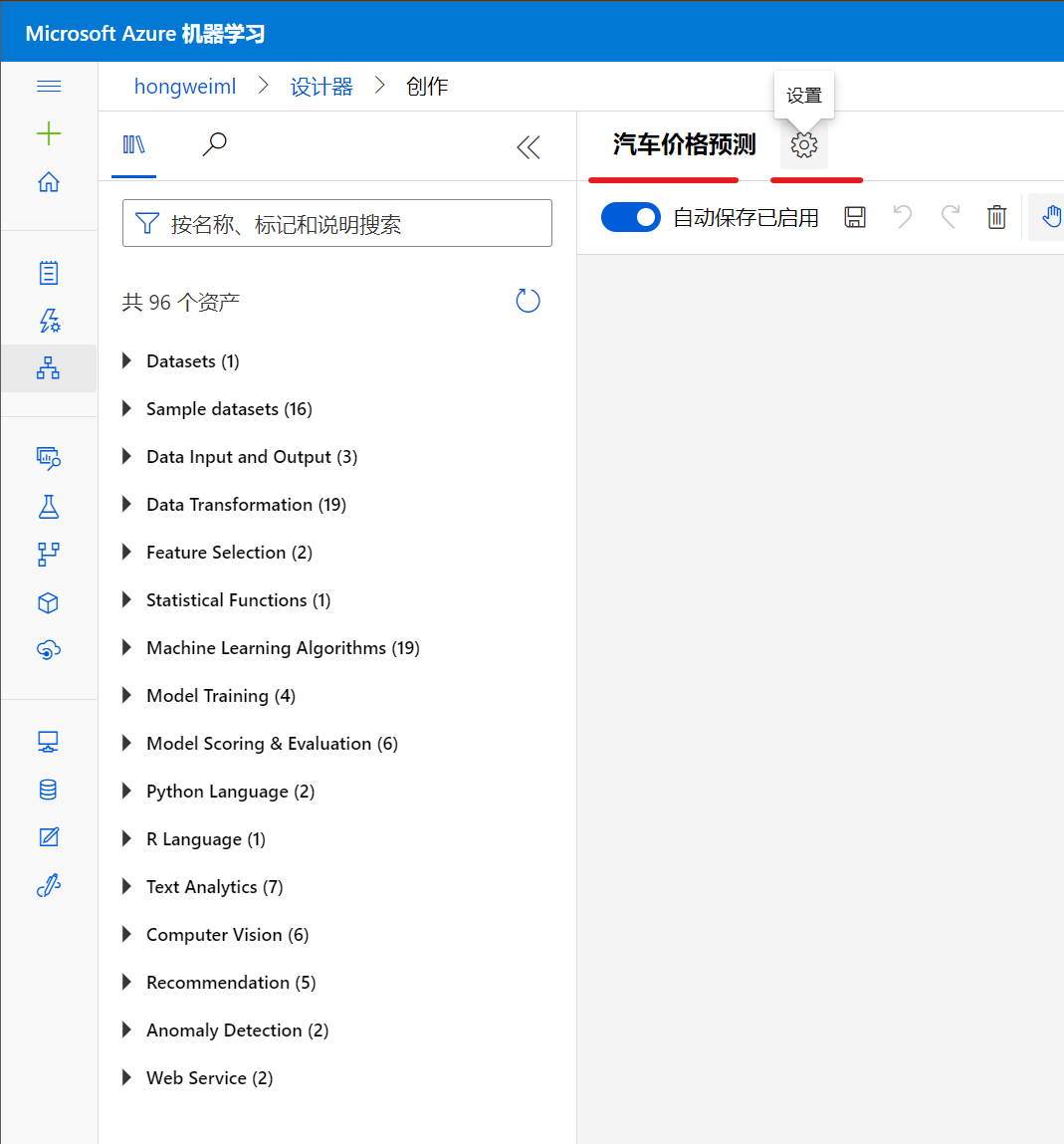
设计默认的计算目标
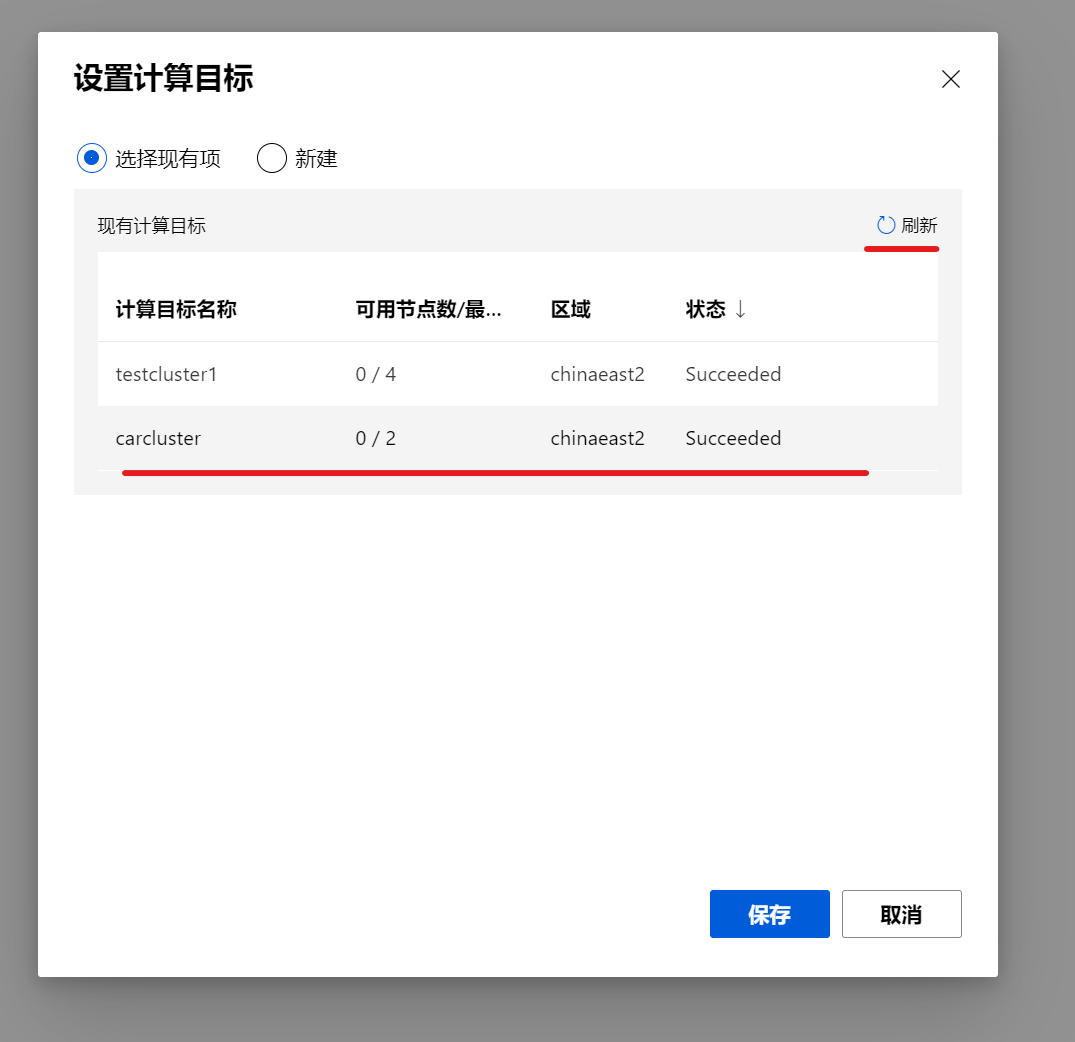
打开设计器的设置面板之后,可以看到最重要的就是要设置整个pipeline默认运行的计算集群:
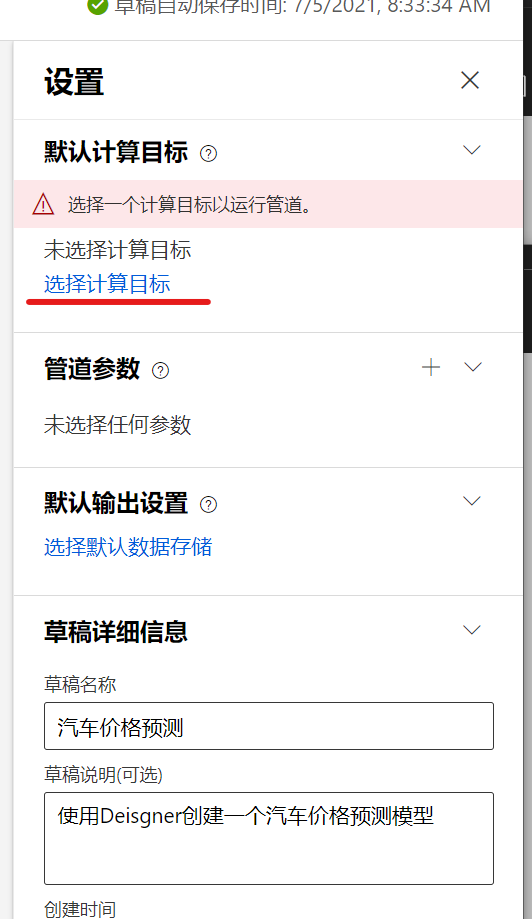
点击选择计算目标, 我们可以选择预定义的计算集群配置,选择新建之后,输入名字,会使用默认配置创建一个集群,如果你不想使用默认配置,也可以事先创建好计算集群,然后在现有集群里选择:
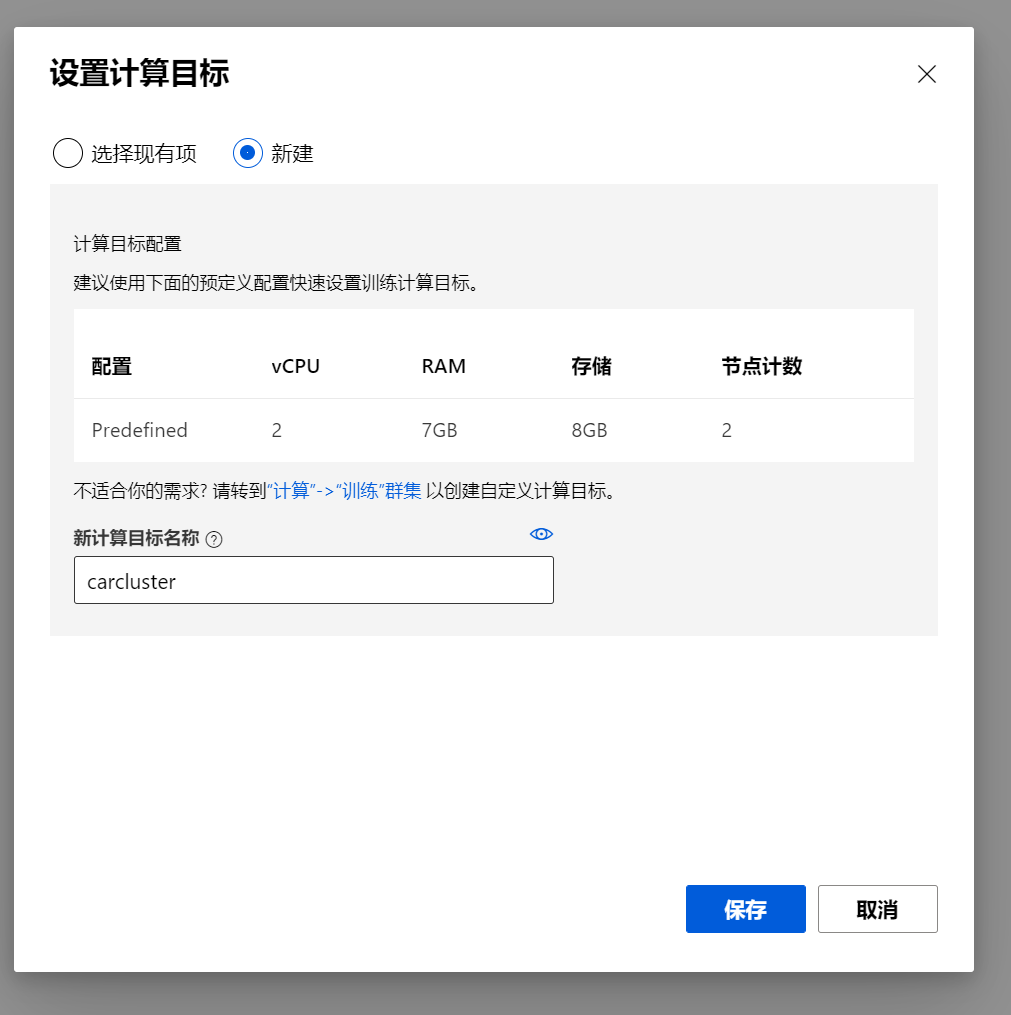
虽然等待创建完成,创建需要一定的时间,可以稍微等一等,点击刷新,等新创建的集群可以使用了,然后保存。
至此我们已经准备好了需要的pipeline的初步设置,也选择好了,默认用于计算的计算集群,接下来我们要开始导入数据了。
导入并处理数据
我们本节使用现有的开源数据集,同时需要对该数据集需要进行如下几个步骤的处理:
- 选择用于训练的数据列
- 清洗缺失的数据
- 拆分数据成两个部分,一个部分用于训练模型,另外一个部分用于模型打分
选择用于训练的数据
这里说一下设计器的基本使用,设计器左边按照不同的功能罗列了很多易于使用的模块,例如数据处理,模型训练等等,你完全可以按照模块的不同划分,一个一个的浏览模块,你也可以通过上面的搜索栏进行模块的搜索,如下图:
, 可以看到目前设计器支持多达96个模块用于机器学习。
我们在本章中要使用开源数据集, 因此你可以找到模块分类Sample Datasets, 并且找到Automobile price data(raw), 然后将该数据模块拖到设计器的画布中,或者你可以直接通过搜索来找到该模块,并拖到画布中
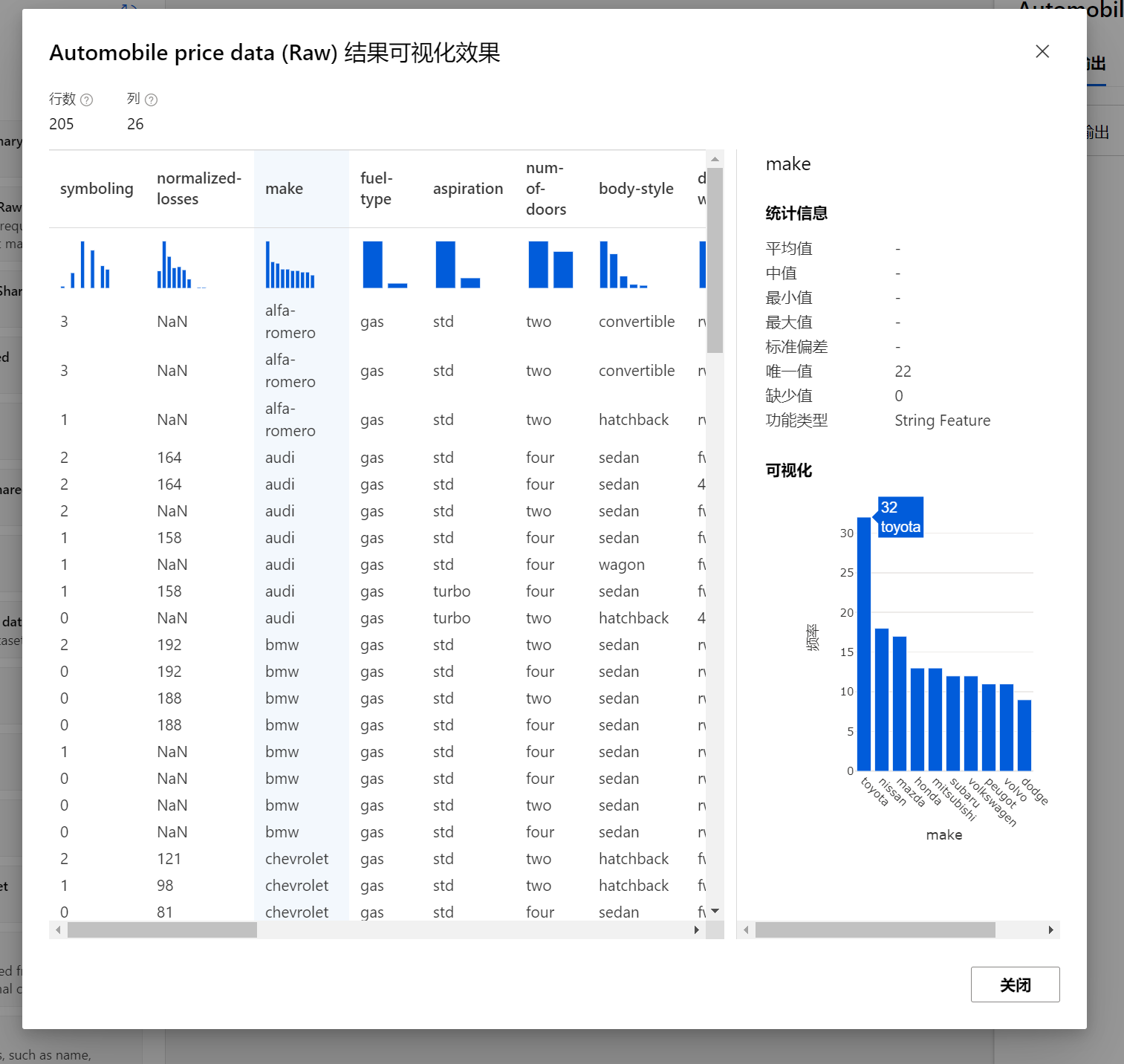
您可以使用输出功能大致查看一下该数据集的基本情况:
选择用于训练的数据列
通过上述介绍的查找模块的功能,找到模块Select Columns in Dataset
并拖到画布中,同时将两个模块按照图中所示链接起来:
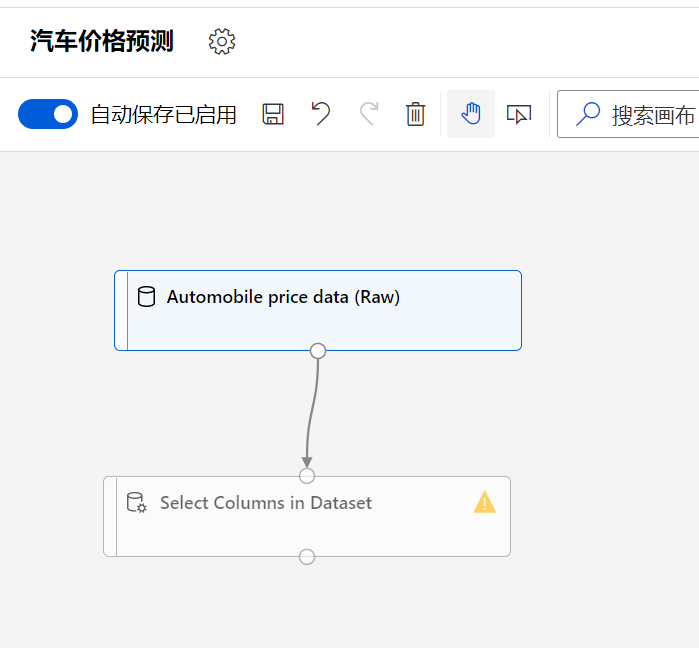
选择模块,出现模块设置属性,然后选择编辑列
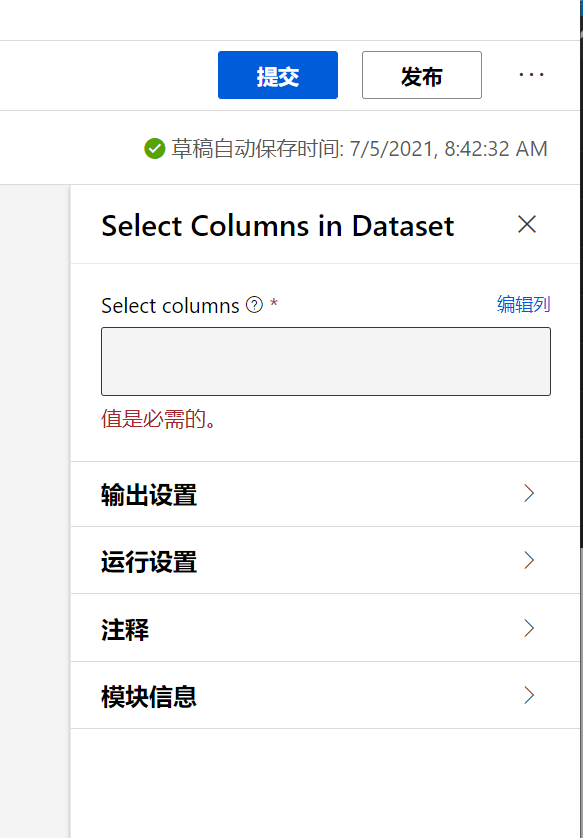
在出现的对话框中,按照下图设置:
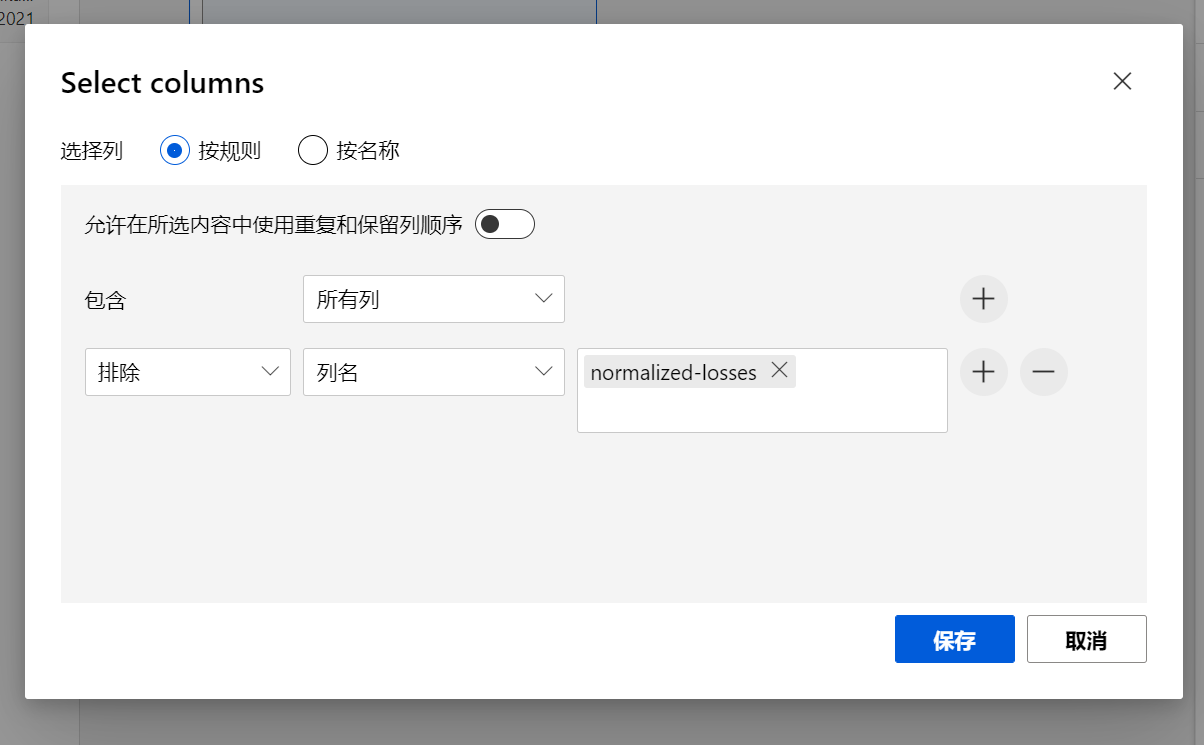
在选择列的对话框中,按照规则来选择,首选包含所有列,然后从所有列中移除列normalized-losses, 点击保存。
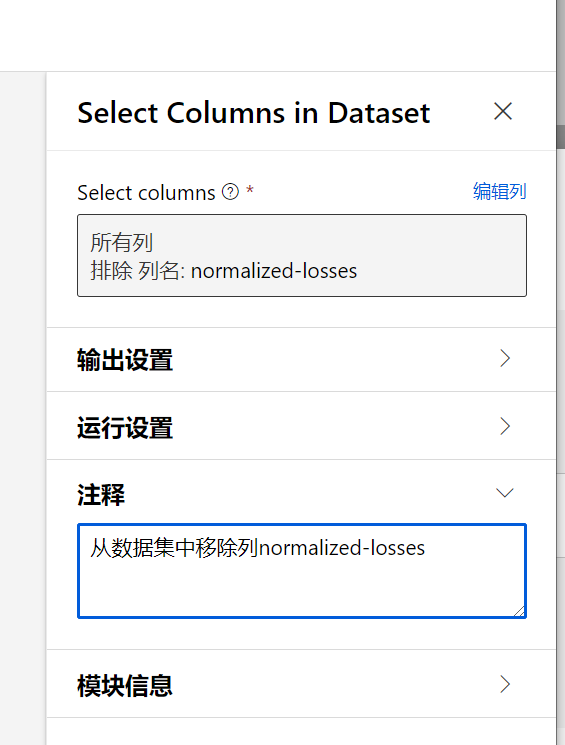
添加注释
清洗数据
我们上一步已经将需要的数据列选择完毕了,那么我们这一步需要处理假如某一列的数据缺失,训练中该如何处理这种情况?
使用搜索的功能找到模块Clean Missing Data, 并拖到画布中,将上一步的模块链接到该模块,并如上一步打开设置的界面, 并选择编辑列, 如上一步,选择所有列,但是这一步我们无需排除任何列,因为在这里我们需要所有的列的数据,保存子厚,回到设置界面,如下图:
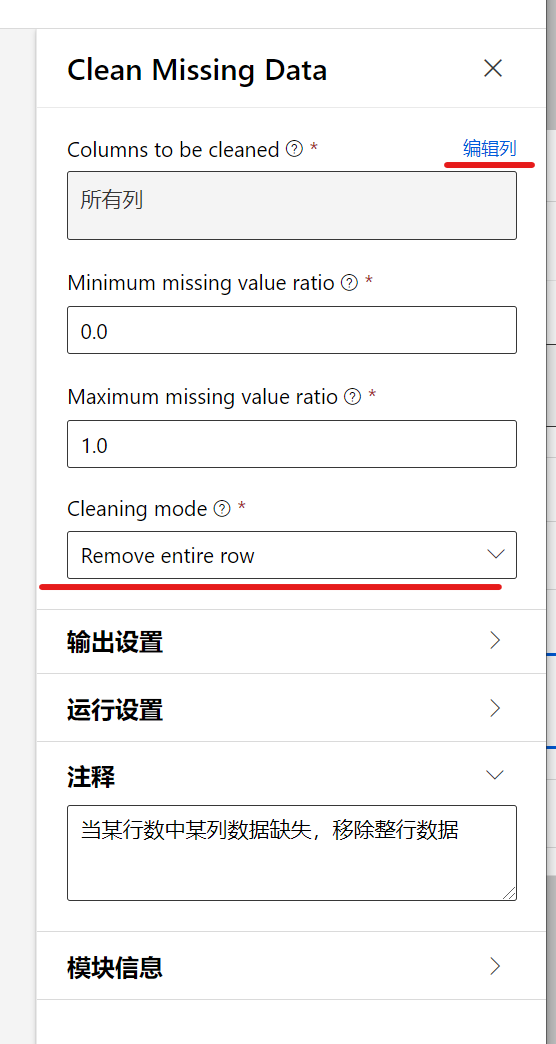
另外我们需要设置Cleaning model, 选择Remove entire row, 表示当某行中,如果有某一列的数据缺失,我们就会移除整行数据。
这样我们完成了数据清洗的动作了。
拆分数据
目前通过选择需要的数据列,并且清洗掉了缺失的数据,我们现在已经有了可以用于训练的数据,我们任然需要再进一步的处理,需要将准备好的数据,拆分为两个部分,一部分用于完成模型训练,另外一部分用于模型的评估。
通过模块搜索找到模块Split Data, 并将它拖放到画布中,点击该模块,显示属性配置,进行如下的配置:
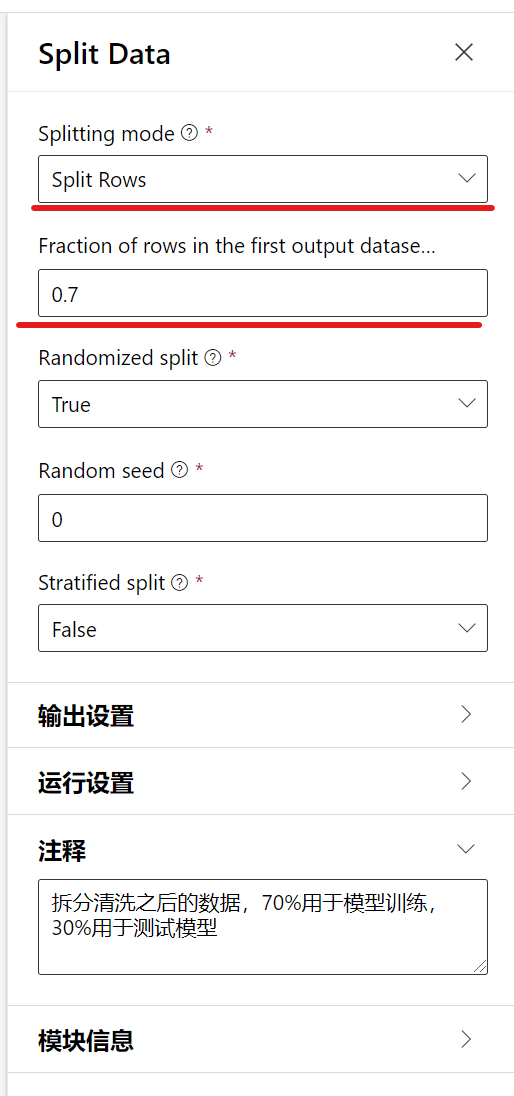
需要注意的是: Splitting mode要选择Split rows, Fraction of rows in the first output dataset中选择0.7, 表示70%的数据用于模型训练,剩下30%的数据,我们保留,后面会用这部分的数据对模型进行打分。
至此我们终于完成了数据预处理的部分,到目前,完成的图如下:
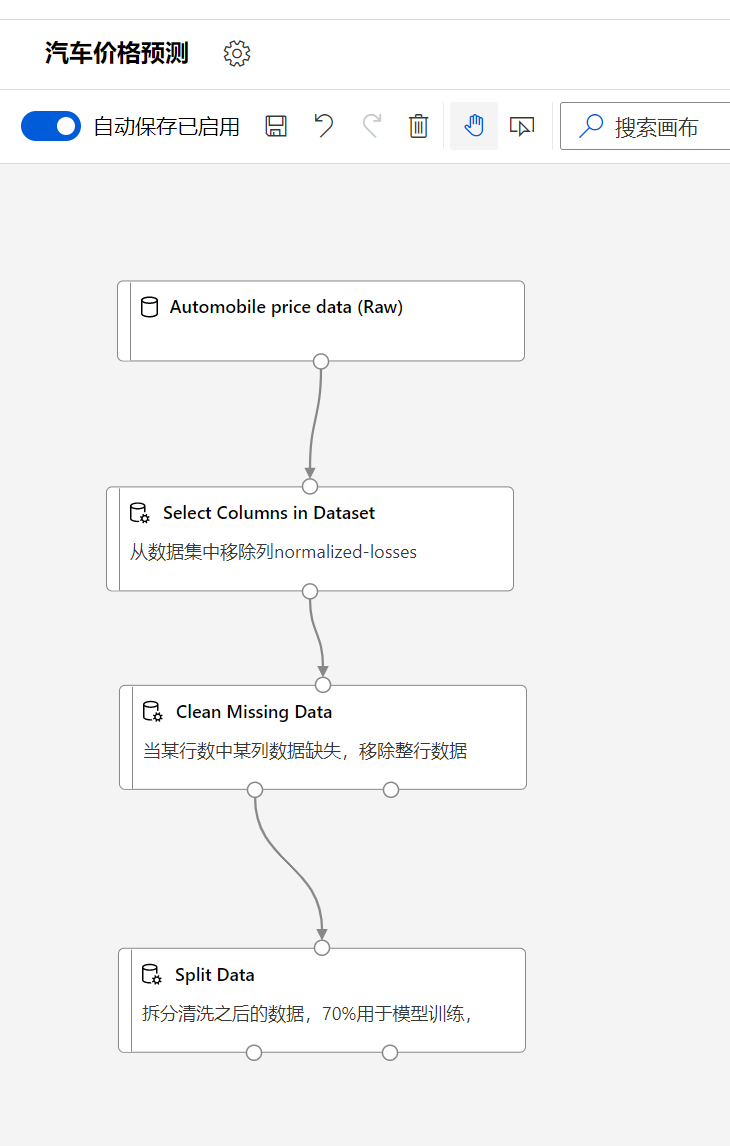
大家一定要注意的是链接每个模块的时候,每个连接线的链接是需要注意的,因为可以观察到Clean missing data的输出是由两个,左边的表示清洗之后的数据,右边表示脏数据,同时Split Data也有两个输出,左边的表示70%, 右边的表示30%
模型训练
我们现在正是开始模型训练了。
设置训练步骤
从模块搜索框里搜索出Train model,模块并拖放到画布中,并将split data和该模块链接起来,这里需要注意该模块有两个数据,数据输出要链接到右边的输入,如下图:
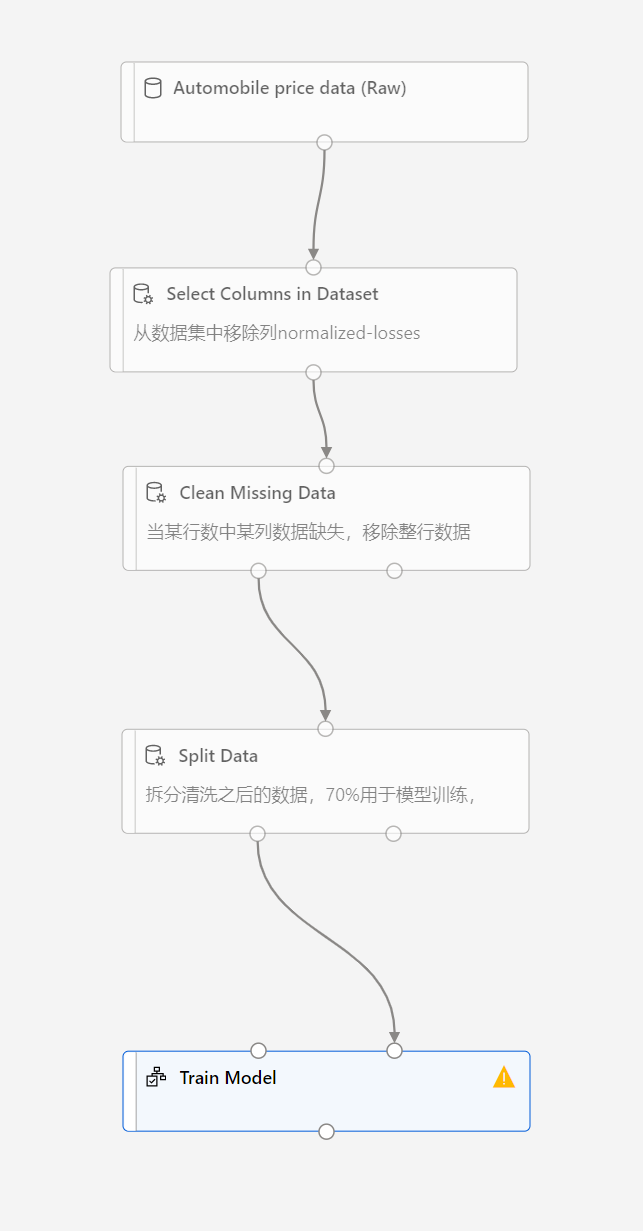
然后选择该Train Model, 出现设置界面,再设置界面编辑列选择需要预测的数据列,我们这里是预测价格,因此选择price
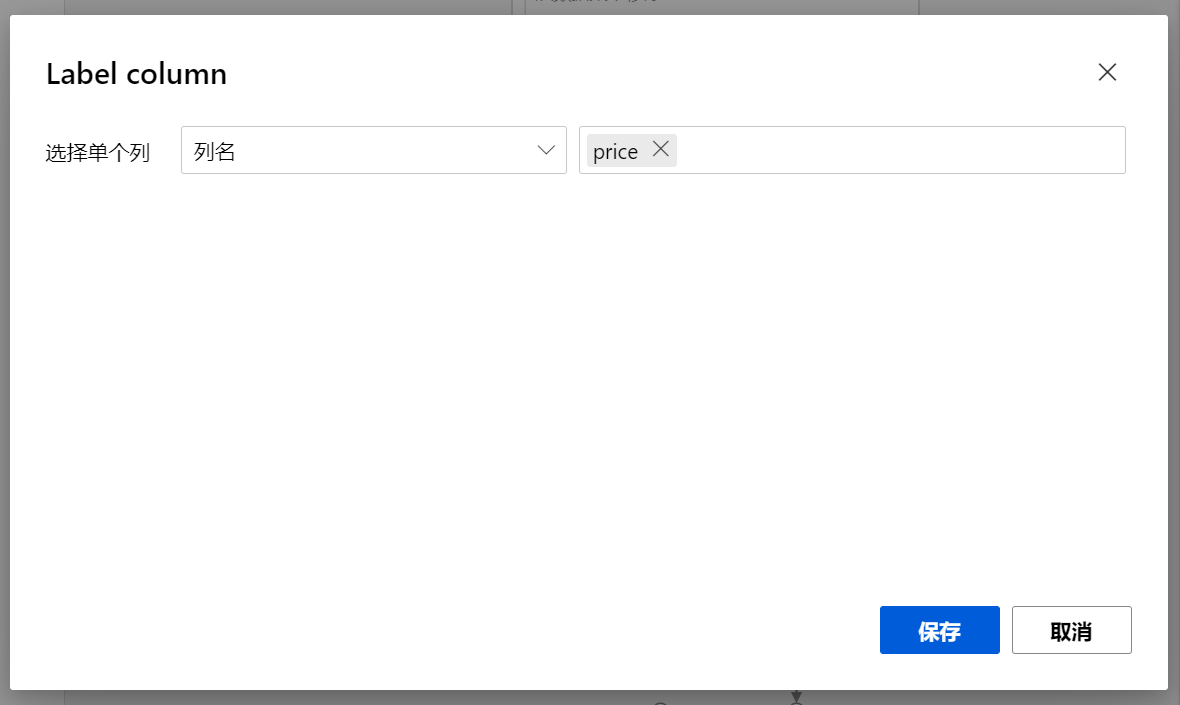
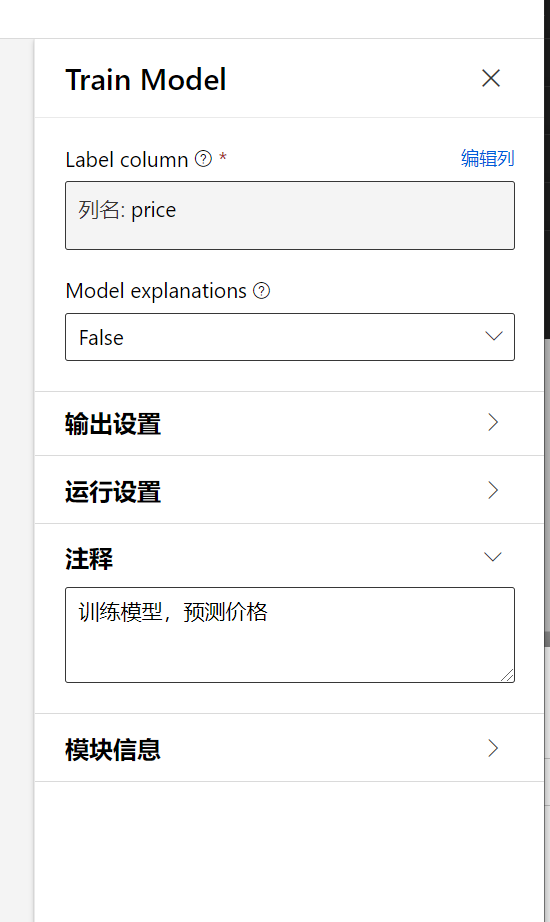
选择算法
我们已经将数据和训练模块链接了,但是还没有为该训练任务选择必要的算法,因此在模块搜索里搜索:Linear, 选择Linear Regression, 并拖放到画布中
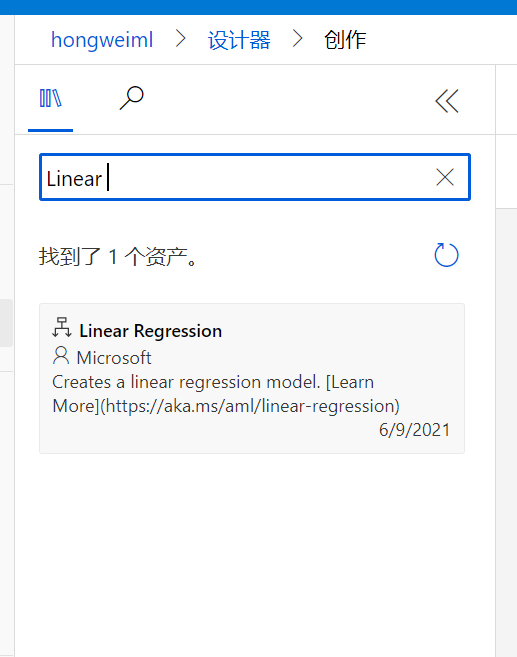
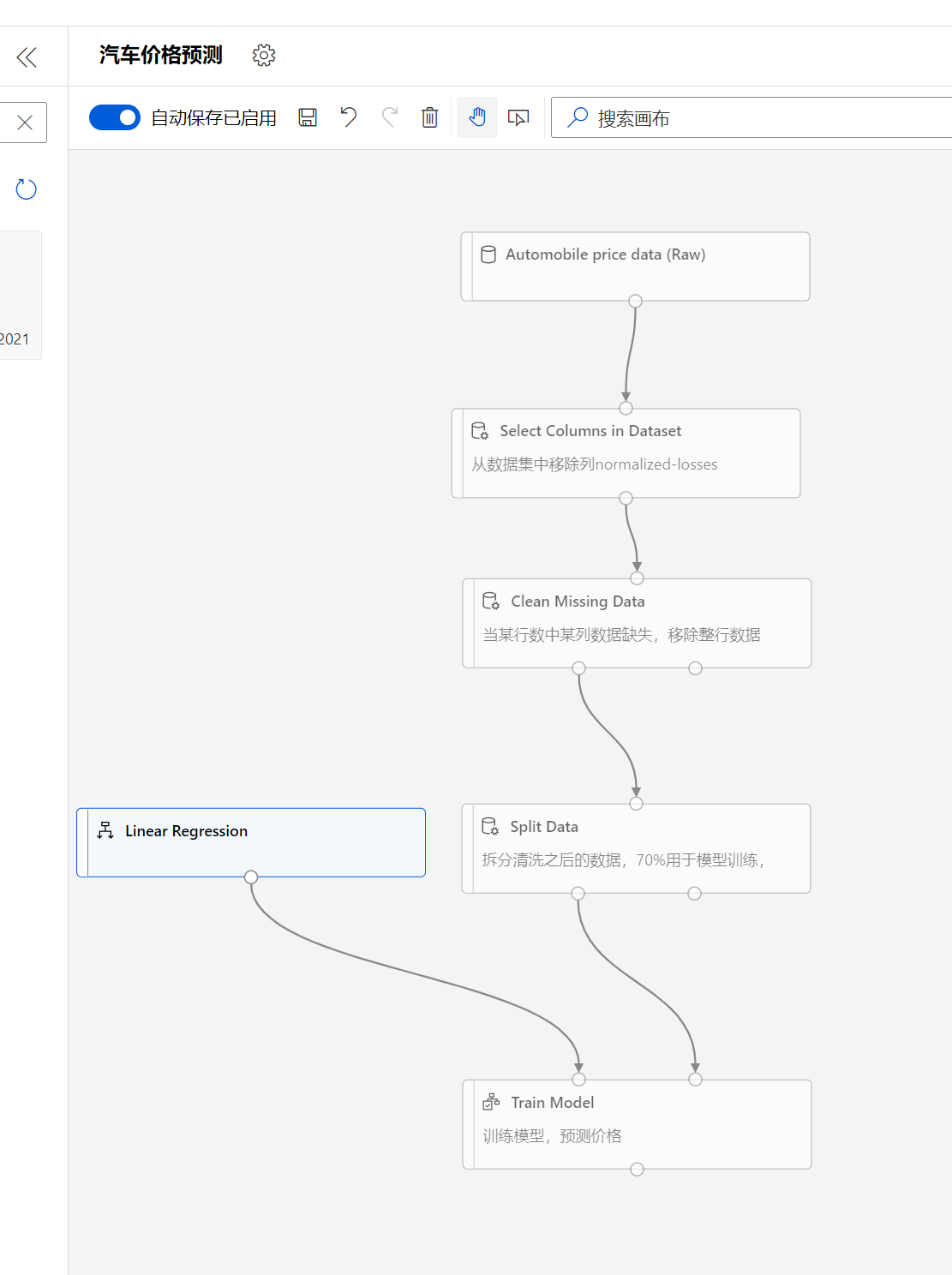
同时将该模块的输出和train model的左侧输入相链接,支持我们已经完成了为训练任务选择算法了。
给模型打分
在模块搜索里搜索Score, 然后选择模块Score Model, 然后拖放至画布中,将train model的输出和该模块的左侧输入链接,同时将Split Data模块的右侧输出和该模块的右侧输入相链接:
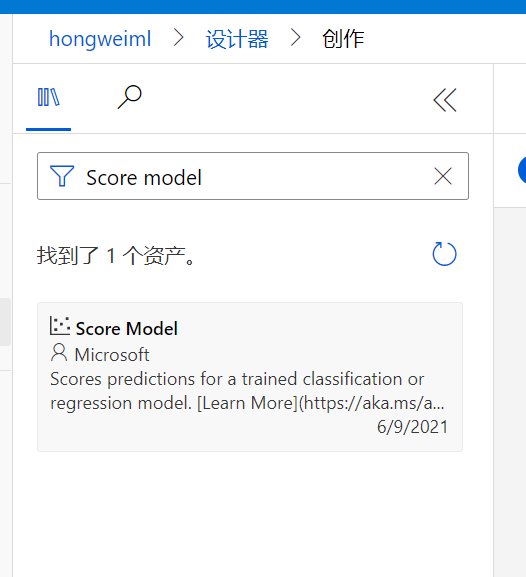
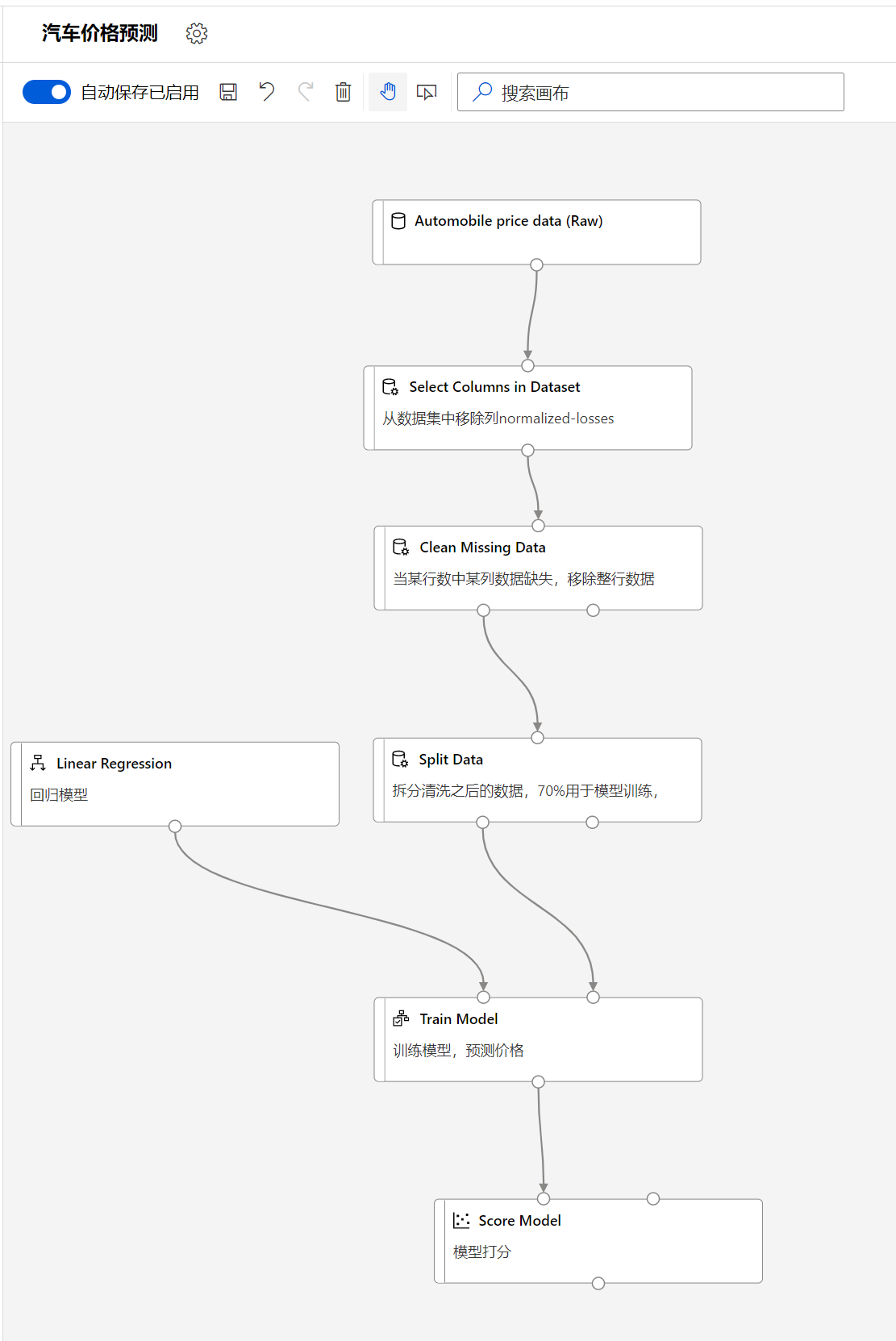
评估模型
搜索并拖放模块Evaluate Model, 同时将Score Model输出和它相连接
最后的完成图如下:
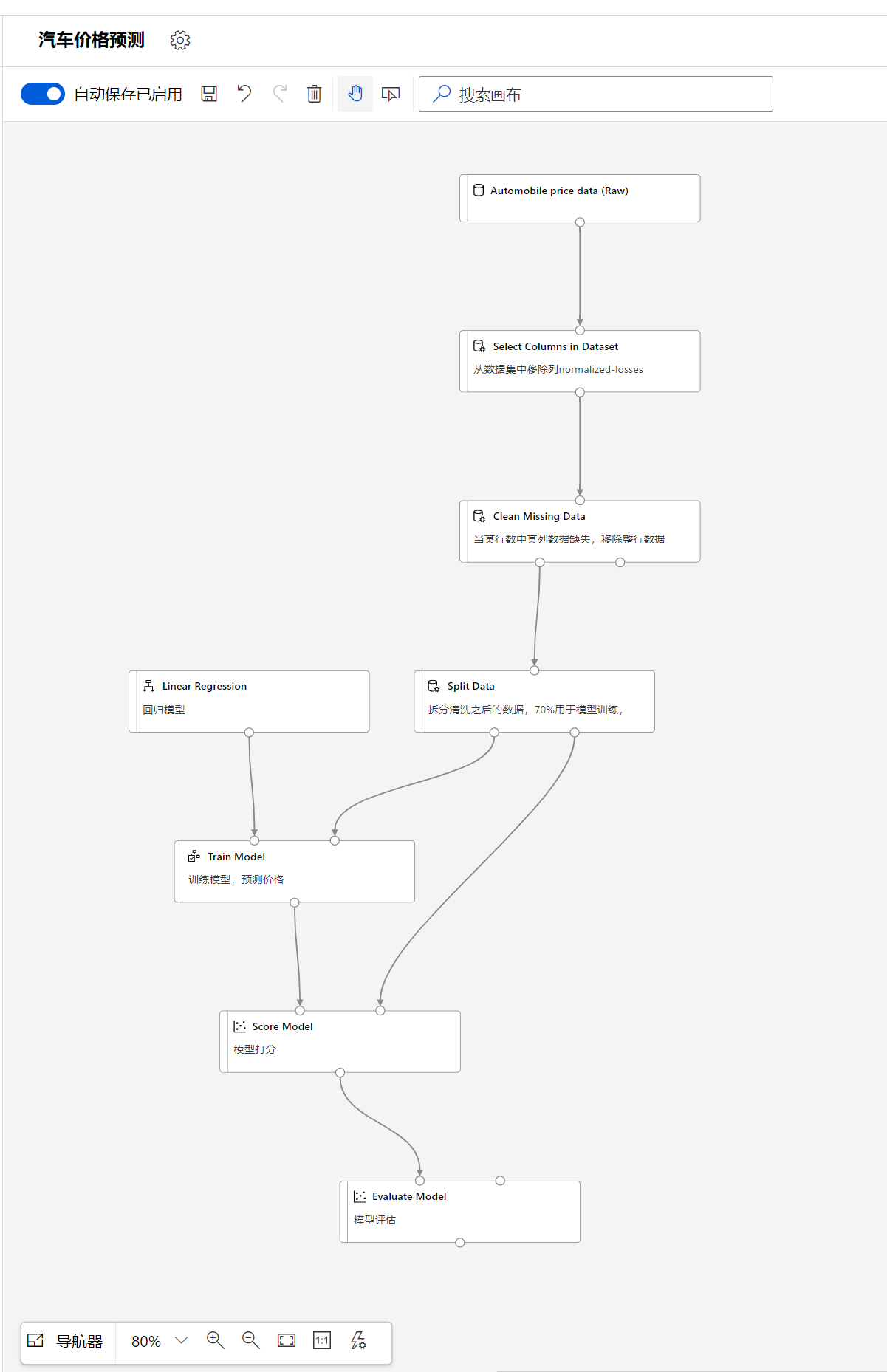
大家可以对比一下自己的设计,特别需要注意连接线的左右连接不能弄错。
训练模型
至此我们终于完成了pipeline的设计,我们前面学习过使用设计器主要的工作就是设计pipeline, 如果我们已经完成了,设计,下一步我们需要将它提交为一个experiment, 然后开始有experiment管理run, 用于模型的训练,打分,评估等动作。
因此我们在画布上测点击提交
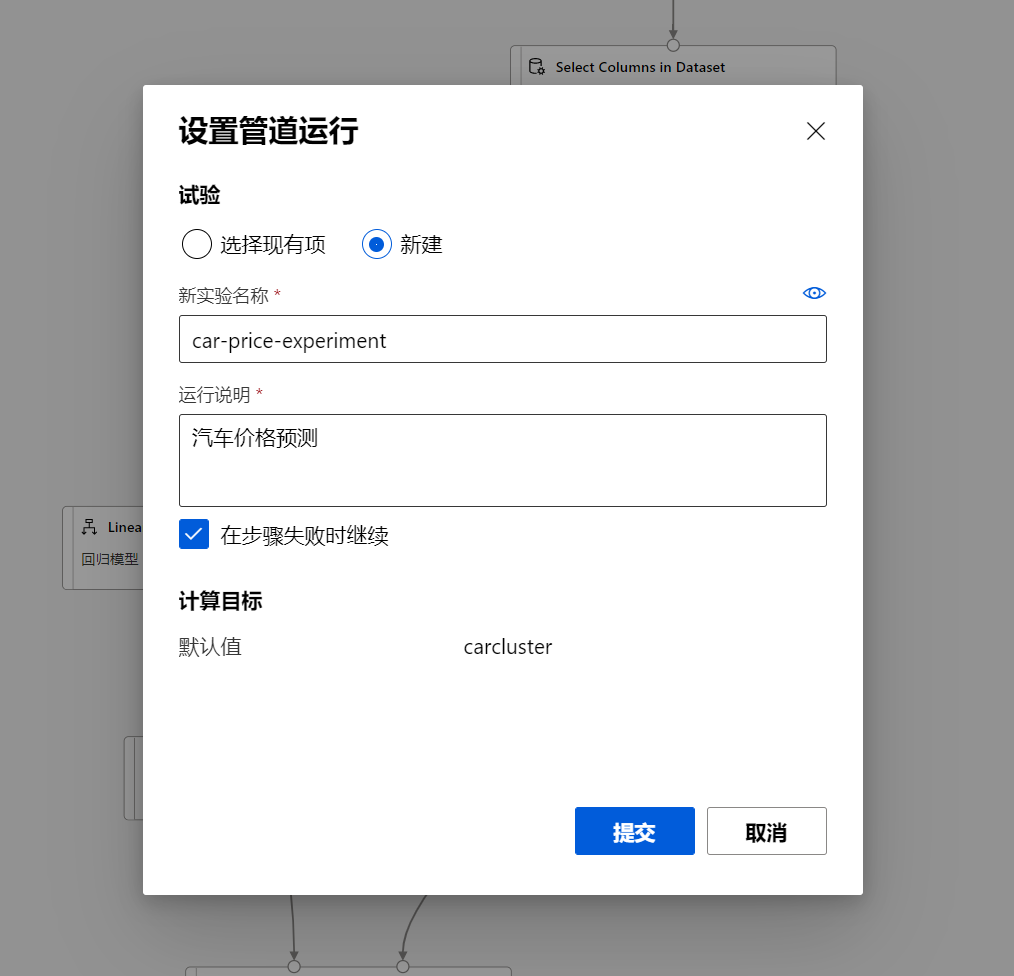
在新出现的对话框中,选择新创建一个Experiment
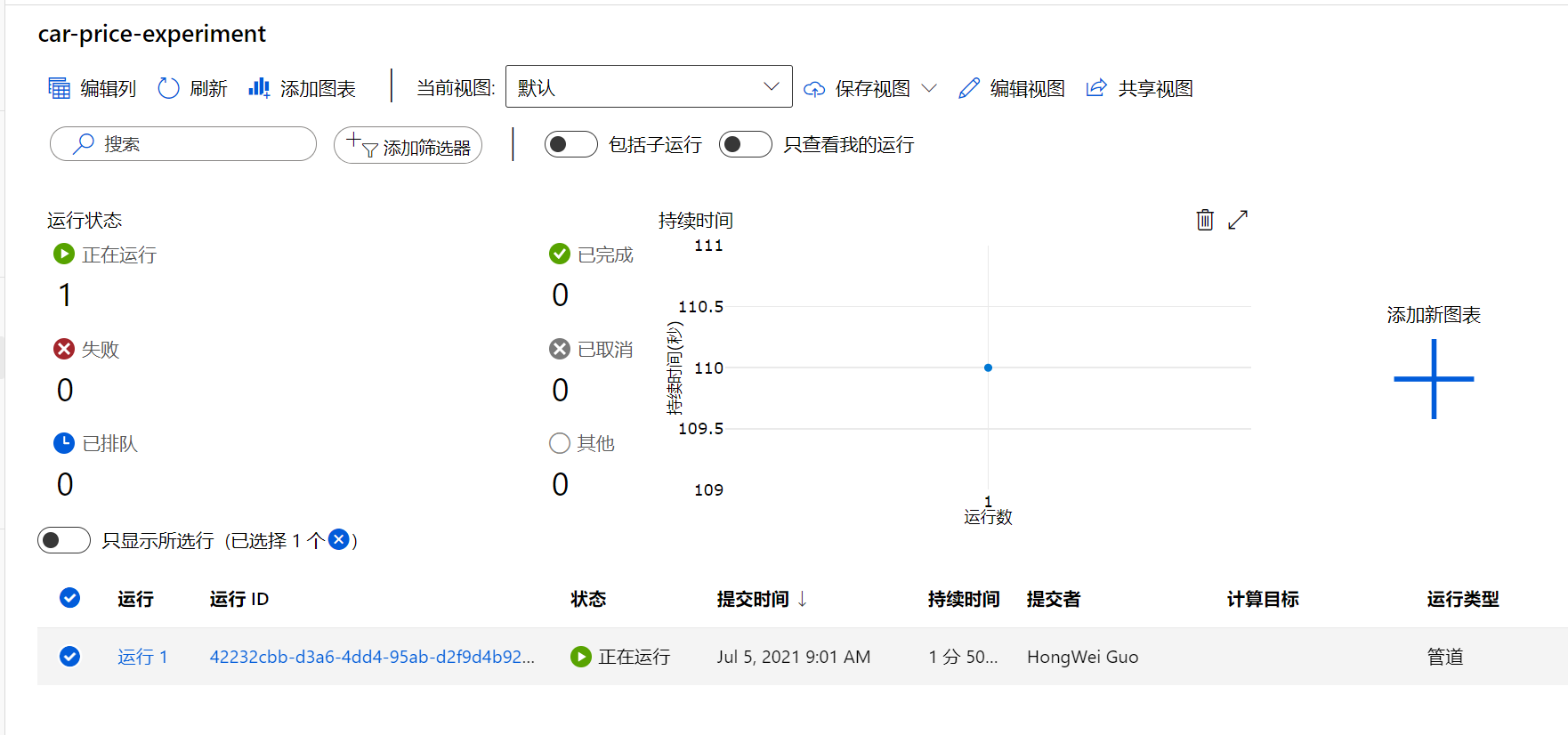
提交后,Azure即开始训练模型,您可以通过左侧菜单实验, 来监控或者观察运行的基本情况。
运行结果评估
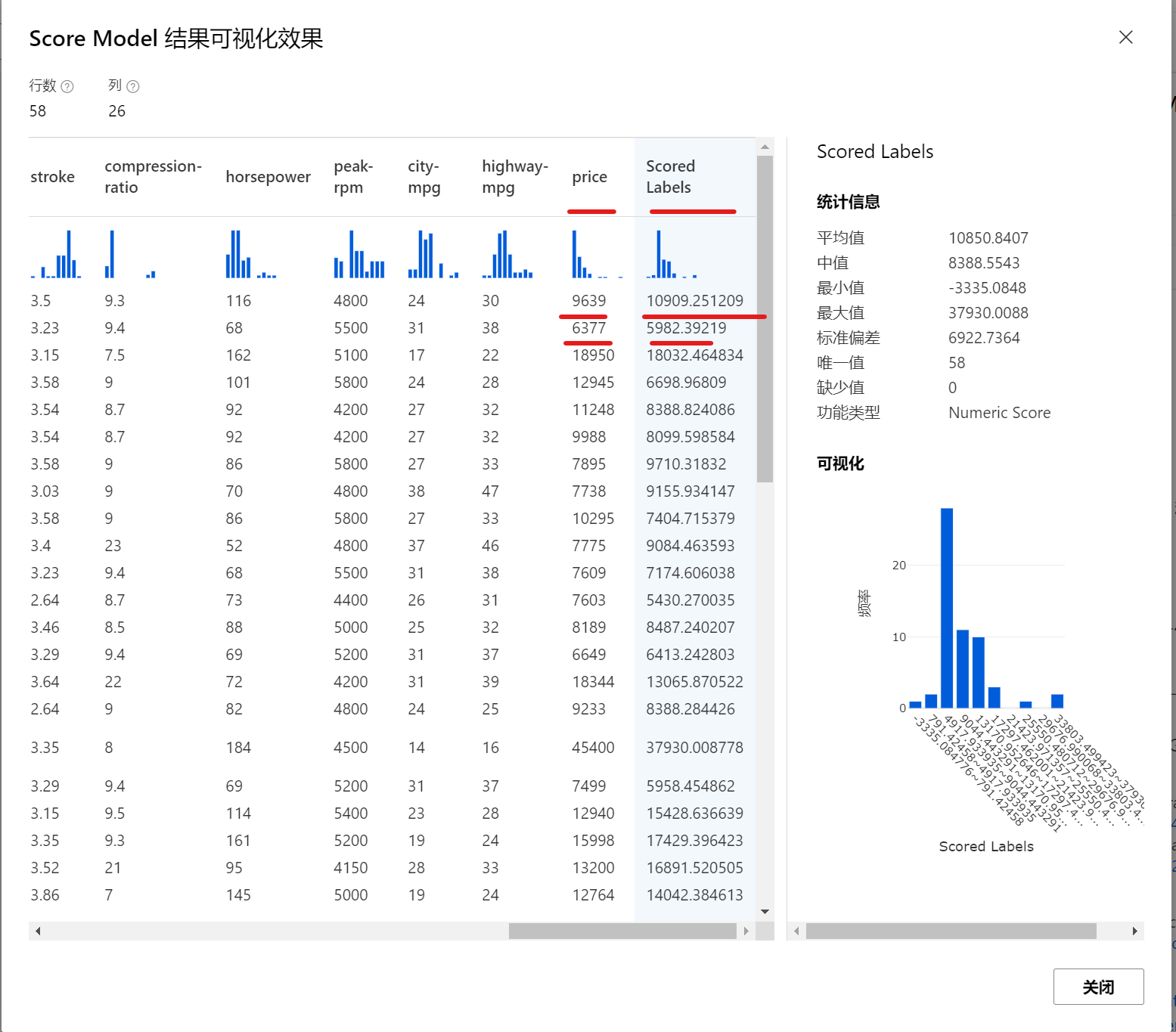
训练结束后,在图形里选择Score Model, 点击右键,选择可视化,即可查看结果:
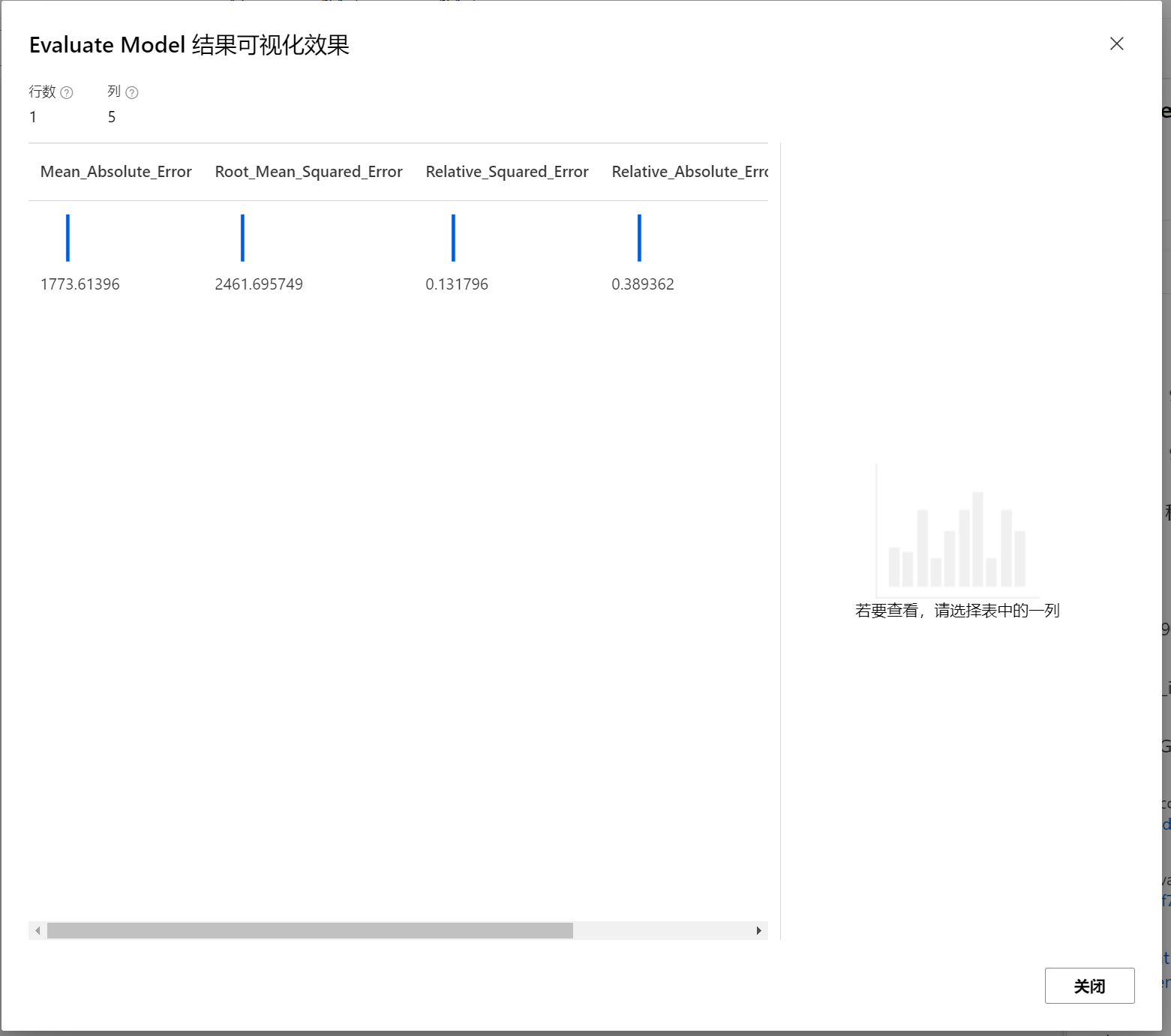
如果需要查看评估结果,在图像里选择Evaluate Model, 然后选择可视化,查看结果:
至此我们完成了第一次通过设计器来完成的模型训练,同样是无需任何代码,设计器可以自有选择支持的算法,支持更多的应用场景,下一节我们将学习如何通过设计器来部署已经训练好的模型。