索引生成器
分类: Azure搜索 ◆ 标签: #Azure #Search #认知搜索 ◆ 发布于: 2023-06-12 20:14:18

Azure认知搜索中的索引器是一种爬虫程序,它从外部 Azure 数据源提取可搜索的文本和元数据,并使用源数据与索引之间字段到字段的映射填充搜索索引。 由于不需要编写任何将数据添加到索引的代码,该服务就能拉取数据,因此这种方法有时也称为拉取模式。 索引器还驱动认知搜索的 AI 扩充功能,在索引的路由中集成对内容的外部处理。
索引器仅适用于 Azure,其中包含适用于 Azure SQL、Azure Cosmos DB、Azure 表存储 和 Blob 存储的单个索引器。 配置索引器时,将指定数据源(原点)和索引(目标)。 Blob 存储等源具有特定于该内容类型的其他配置属性。
可以按需运行索引器,也可以采用每 5 分钟运行一次的定期数据刷新计划来运行索引器。 要进行更频繁的更新,则需要采用“推送模式”,便于同时更新 Azure 认知搜索和外部数据源中的数据。
支持的数据源
索引器在 Azure 上和 Azure 外部抓取数据存储。
- Amazon Redshift(预览版)
- Azure Blob 存储
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Azure MySQL(预览版)
- Azure SQL 数据库
- Azure 表存储
- Elasticsearch(预览版)
- PostgreSQL(预览版)
- Salesforce Objects(预览版)
- Salesforce Reports(预览版)
- Smartsheet(预览版)
- Snowflake(预览版)
- SQL 托管实例
- Azure 虚拟机中的 SQL Server
可以使用标准的 Internet 连接(公共),或者在将 Azure 虚拟网络用于客户端应用时使用加密的专用连接,以实现索引器与远程数据源的连接。 还可以建立使用可信服务标识进行身份验证的连接。 有关安全连接的详细信息,请参阅通过专用终结点授予访问权限和使用托管标识连接到数据源。
索引阶段
在首次运行时,如果索引为空,索引器将读取表或容器中提供的所有数据。 在后续运行中,索引器通常可以只检测并检索已更改的数据。 对于 blob 数据,更改检测是自动进行的。 对于其他数据源(如 Azure SQL 或 Cosmos DB),必须启用更改检测。
对于它接收的每个文档,索引器将执行或协调多个步骤来编制索引,从文档检索到最终的搜索引擎“移交”。 索引器还可以驱动技能组执行和输出(假设定义了技能组)。

第1阶段:文档破解
文档破解是打开文件并提取内容的过程。 可以从服务上的文件、表中的行或容器或集合中的项提取基于文本的内容。 如果将技能组和图像技能添加到索引器,文档破解还可以提取图像并让其排队等待处理。
索引器会根据数据源尝试不同的操作来提取潜在的可索引内容:
当文档是文件时(例如,文件是 PDF 格式或 Azure Blob 存储中支持的其他文件格式),索引器会打开该文件并提取文本、图像和元数据。 索引器还可以从 SharePoint 和 Azure Data Lake Storage Gen2 打开文件。
当文档是 Azure SQL 中的记录时,索引器会从每条记录的每个字段中提取非二进制内容。
当文档是 Cosmos DB 中的记录时,索引器会从 Cosmos DB 文档的字段和子字段中提取非二进制内容。
第 2 阶段:字段映射
索引器提取源字段中的文本,并将其发送到索引或知识存储中的目标字段。 当字段名称和类型一致时,路径会被清除。 不过,如果希望输出中有不同的名称或类型,则需要告知索引器如何映射字段。
当索引器从源文档读取时,此步骤需在文档破解后、转换之前进行。 在定义字段映射时,源字段的值将按原样发送到目标字段,而不进行任何修改。
第 3 阶段:技能组执行
技能组执行是一个可选步骤,它调用内置或自定义 AI 处理。 如果源数据是二进制图像,则可能需要它以图像分析的形式进行光学字符识别 (OCR),或者如果内容采用不同的语言,则可能需要语言翻译。
无论是哪种转换,技能组执行都是扩充的途径。 如果索引器是管道,则可将技能组视为“管道内的管道”。
阶段 4:输出字段映射
如果包括技能组,则很可能需要包含输出字段映射。 技能组的输出实际上是一棵称为“扩充文档”的信息树。 通过输出字段映射,可以选择此树中哪些部分要映射到索引中的字段。 了解如何定义输出字段映射。
输出字段映射会指示索引器如何将扩充文档中已转换的值关联到索引中的目标字段,但是字段映射会将数据源中的逐字值关联到目标字段。 与被视为可选的字段映射不同,你始终需要为需要驻留在索引中的任何已转换内容定义输出字段映射。
下图显示了索引器不同阶段的示例索引器调试会话的表示形式:“文档破解”、“字段映射”、“技能组执行”和“输出字段映射”。
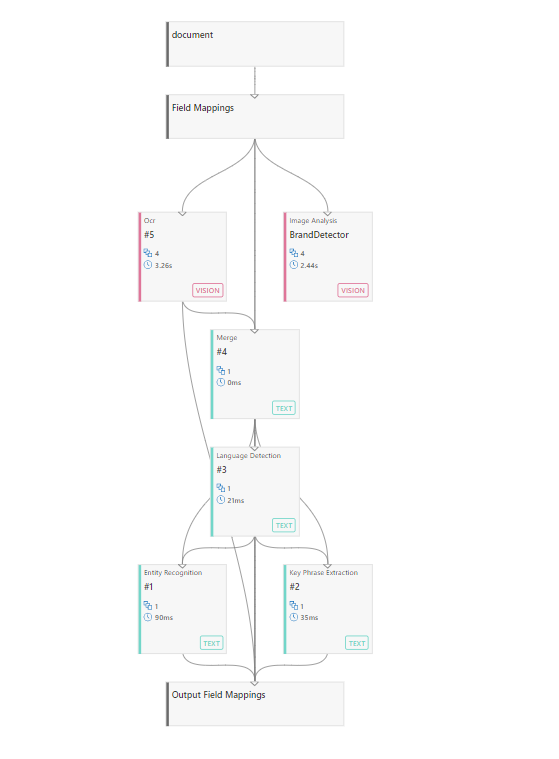
基本工作流程
索引器可提供数据源独有的功能。 因此,索引器或数据源配置的某些方面会因索引器类型而不同。 但是,所有索引器的基本构成元素和要求都相同。 下面介绍所有索引器都适用的共同步骤。
步骤 1:创建数据源
索引器需要提供连接字符串的数据源对象和可能的凭据。 调用创建数据源 (REST) 或 SearchIndexerDataSourceConnection 类以创建资源。
数据源的配置和管理独立于使用数据源的索引器,这意味着多个索引器可使用一个数据源,同时加载多个索引。
步骤 2:创建索引
索引器会自动执行某些与数据引入相关的任务,但通常不会自动创建索引。 先决条件是必须具有预定义的索引,且索引的字段必须与外部数据源中的字段匹配。 字段需按名称和数据类型进行匹配。 如果不是,可以定义字段映射以建立关联。 有关构建索引的详细信息,请参阅创建索引 (REST) 或 SearchIndex 类。
提示
虽然不能使用索引器来生成索引,但可以使用门户中的 导入数据 向导。 大多数情况下,该向导可以根据源中现有的元数据推断索引架构,提供一个初级索引架构,该架构在向导处于活动状态时可以进行内联编辑。 在服务上创建索引以后,若要在门户中进一步进行编辑,多数情况下只能添加新字段。 可以将向导视为索引的创建工具而非修订工具。 如需手动方式的学习,请一步步完成门户演练。
步骤 3:创建和运行(或计划)索引器
在搜索服务上首次创建索引器时,该索引器会运行。 只有在创建或运行索引器时,才会发现数据源是否可以访问,或者技能组是否有效。 首次运行后,可以使用运行索引器按需重新运行它,也可以定义定期计划。
可以通过门户或获取索引器状态 API 监视索引器状态。 还应对索引运行查询,以验证结果是否符合预期。