全文搜索的基本概念
分类: Azure搜索 ◆ 标签: #Azure #Search #认知搜索 ◆ 发布于: 2023-06-12 20:04:55

Azure认知搜索底层集成了Lucene, 同时微软也提供了自己的技术,但是总体来说很多方面都还是用了Lucene, 因此Azure认知搜索同样遵行Lucene的四个阶段:查询分析, 词法分析, 文档匹配, 搜索结果评分。
本章只是简单的介绍一下Lucene的搜索的基本知识,方便大家在使用Azure认知搜索时遇到问题,会有比较明确的方向。
我们先来看几个基本的概念:
- 查询词:查询词是指客户输入的需要查询的语句,需要注意的是,即便是简单的查询词,也可能会被分解并重排。
- 搜索词:从查询词中提取的词语。
- 匹配词: 我的理解是同搜索词。
- 相关性评分:是指搜索引擎通过索引匹配之后,根据相关性对结果的打分,评分靠前的会返回给调用者。
我们前面说过了查询执行时包括四个阶段:
- 查询分析
- 词法分析
- 文档检索
- 计分
我们可以快速的用如下的图来演示各组件之间的关系:
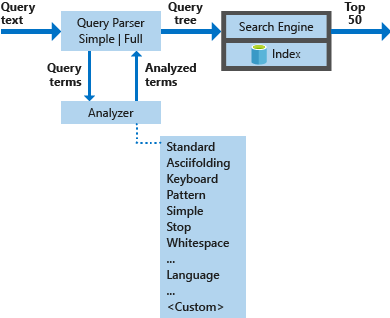
从这个图例我们可以看到查询执行过程中涉及到四个组件:
- 查询分析器: 主要作用是将查询词和查询运算符区分开来,并创建要发送到搜索引擎的查询结构 - 即查询树
- 分析器: 主要目的是针对查询词执行词法分析,这个过程中可能会涉及到查询词的转换,删除或者扩展。
- 索引: 索引的数据结构,用于存储和组织从索引文档中提取的可搜索词。
- 搜索引擎: 根据倒排索引的内容检索文档并为其评分。
搜索请求的分析
针对于每个搜索的请求,Lucene和Azure认知搜索都是要求有一个标准的规范,虽然客户在用户界面上输入是无需任何的规范,但是对于开发者来说,必须理解规范的存在,这个规范主要用于:
- 向搜索引擎提供用户的输入查询词。
- 指定需要搜索的字段。
- 指定过滤和筛选的条件
- 指定搜索的模式
- 指定查询的类型
- 指定排序模式
如下是一个标准的通过PostMan来请求Azure认知搜索的请求格式:
POST /indexes/hotels/docs/search?api-version=2020-06-30 { "search": "Spacious, air-condition* +\"Ocean view\"", "searchFields": "description, title", "searchMode": "any", "filter": "price ge 60 and price lt 300", "orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')", "queryType": "full" }
下面我们来看一下查询执行的几个阶段:
第一阶段:查询分析
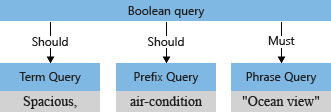
我们以前面提出的一个实例来继续学习如何对做查询分析, 我们的查询词是:
"search": "Spacious, air-condition* +\"Ocean view\"",
查询分析器会将运算符和搜索词区分开,并将搜索查询词解构成受支持的子查询:
- 针对对立字词的字词查询。
- 针对带引号的字词的短语查询:注意带引号会被认为是一个查询短语。
- 针对字词前后接前后缀运算符的前缀查询。
在搜索查询词中用户可以使用运算符来指定一些必须的操作,例如在查询分析器解构了搜索词之后,搜索引擎需要了解该查询词是必须在文章包含,还是应该被包含,例如 +\"Ocean View\", 因为前导有一个+运算符,因此这个短语是必须包含在文档中的,才会被视为匹配。
根据我们前面的例子,第一阶段查询分析器重新构造成的查询树,可以使用下图来表示:
支持的分析器
Azure认知搜索公开了两种不同的查询语言: Simple(默认)、full。 通过在搜索请求中指定参数queryType来指定哪种查询语言。查询分析器用于解释运算符和语法。
searchMode对分析器的影响
该参数主要是用于指定搜索词之间的逻辑关系,例如默认searchMode的值为any, 即表明如下的搜索关系:
Spacious,||air-condition*+"Ocean view"
其中需要注意的是显示运算符(+)在布尔查询中是没有歧义的,它表示必须包含这个短语。
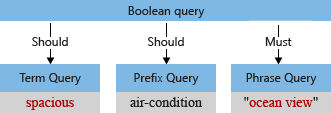
第二阶段: 词法分析
在查询分析器构造查询树之后,词法分析器会处理字词查询和短语查询,词法分析器接受查询分析器提供给它的文本输入,处理文本,并返回标记化的字词,以便在查询树中整合。
词法分析器最常见的形式是语言分析,主要目的是:
- 将查询词简化为单词的词根形式
- 删除不必要的单词(非索引字)
- 将符合词分解为不同的组成部分。
- 转换单词的大小写。
不过由于每一种语言的语法都不同相同,因此词法分析器的作用也是不一致的,也要根据所选择的语言不同来重新看待词法分析器的作用。
词法分析器处理后的查询树:
注意
词法分析仅仅适用于需要完整字词的查询类型:字词查询或者短语查询,但是不适用于不完整的字词查询类型,例如:前缀查询,通配符查询,正则表达式查询,模糊查询。这些查询会直接添加到查询树种,绕过词法分析。唯一会被操作的是转换大小写。另外也需要注意的是词法分析最后也仅仅是再附加会查询树。
第三阶段: 文档检索
文档检索实际上是利用索引对文档进行匹配。那么索引是如何编制的呢?
实际上在文档录入到搜索引擎中的时候,大多数的时候会使用相同的查询分析器,词法分析其对文档进行扫描,然后建立索引,以及索引和文档的对照, Azure认知搜索通过附加indexAnalyzer和searchAnalyzer字段参数来指定使用不同的分析器执行索引和搜索。如果未指定,使用设置分析器analyzer属性用于索引和搜索。
有了索引和文档的映射之后,其他的就是搜索算法了。这个容易理解。
第四阶段:计分
实际上我们已经在第三个阶段拿到了文档匹配的结果集了,但是在返回给用户之前,我们还有一个步骤就是相关性评分,通过该相关性评分能够有效的提高用户的搜索体验。而评分是根据匹配的字词通缉属性来计算的,核心的公式是TF/IDF,有兴趣的同学可以自行研究一下这个评分的公式。
同时Azure认知搜索提供评分优化的建议:
- 通过评分配置文件设定一些规则提升结果中的某些文档的排名(想想百度的竞价排名吧)。
- 字词提升(这个只能在完整的
Lucene查询语法中使用)。
后面我们再继续学习这个两个技能。
以上就是我们在学习Azure认知搜索需要提前了解的一些基本知识点。