Azure 光学字符识别介绍和入门(OCR)
分类: Azure认知服务 ◆ 标签: #Azure #OCR #人工智能 ◆ 发布于: 2023-06-10 22:13:54

OCR(Optical Character recognition)光学字符识别是微软AI研发成果的有一个功能强大的产品,主要的功能是从图片或者PDF文档中提取文字,包括印刷体的图片和手写体的图片或者文档,目前的API关于手写体的识别仅支持英文手写。
OCR有两种API, 新的Read API目前版本是3.0, 印刷体识别目前支持73种语言。关于文档的支持:
- 支持格式: JPEG, PNG, BMP, PDF, TIFF
- 对于PDF和TIFF文档,最多能处理2000个页面。(免费只支持两个页面)
- 文件的大小不能超过50M,图片尺寸在50*50 至 10000 * 10000 个像素之间。
关于支持的语言可以参考这个链接:https://docs.microsoft.com/zh-cn/azure/cognitive-services/computer-vision/language-support#optical-character-recognition-ocr
主要的功能:
- 73 种语言的打印文本提取
- 英语手写文本提取
- 具有位置和置信度分数的文本行和字词
- 不需要语言标识
- 支持混合语言、混合模式(打印和手写)
- 从大型多页文档中选择页面和页面范围
- 文本行的自然阅读顺序
- 文本行的手写分类
- 本地部署可用的 Distroless Docker 容器
OCR入门介绍
开始使用ORC read API之前,需要一个Azure的订阅账号,然后创建Compute Vision资源。
创建Compute Vision资源
登录到Azure Portal之后,在Marketplace中搜索compute Vision, 搜索出之后,点击创建,如下图:
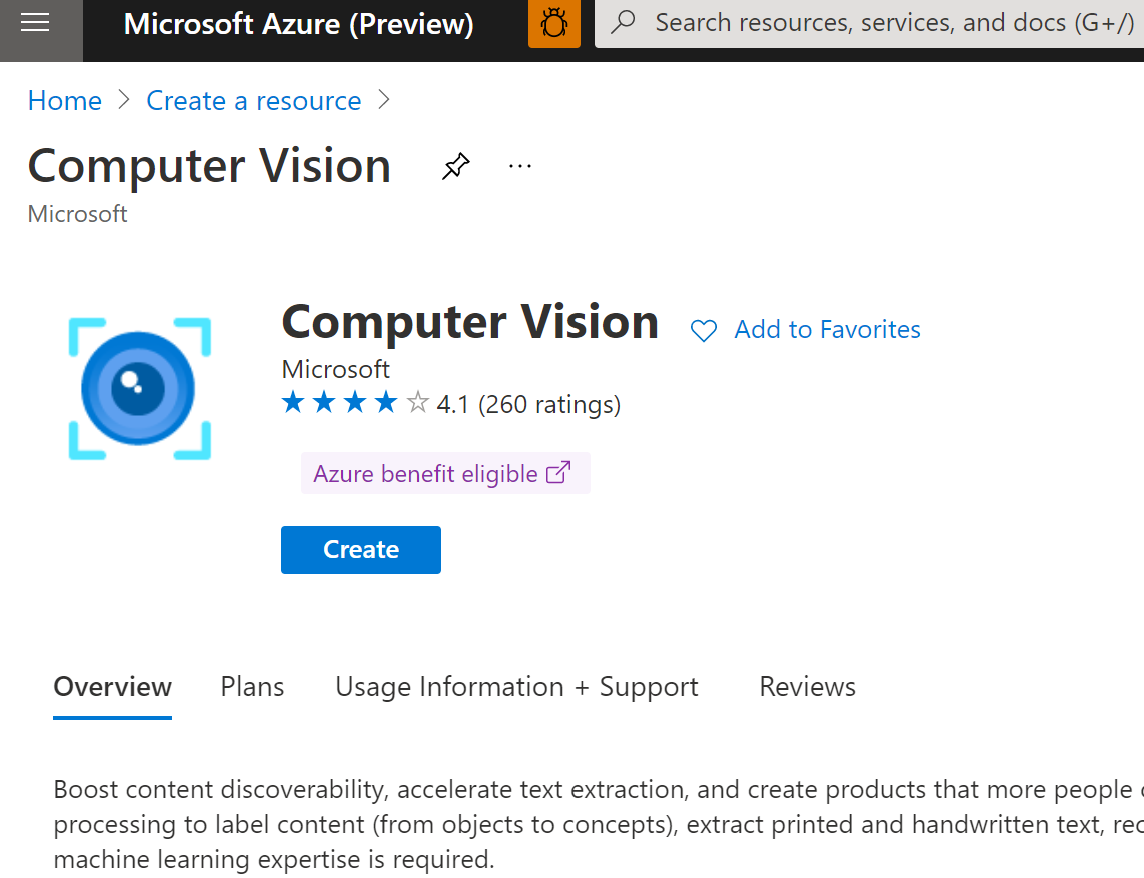
点击创建之后,出现的对话框中填写必要的信息:
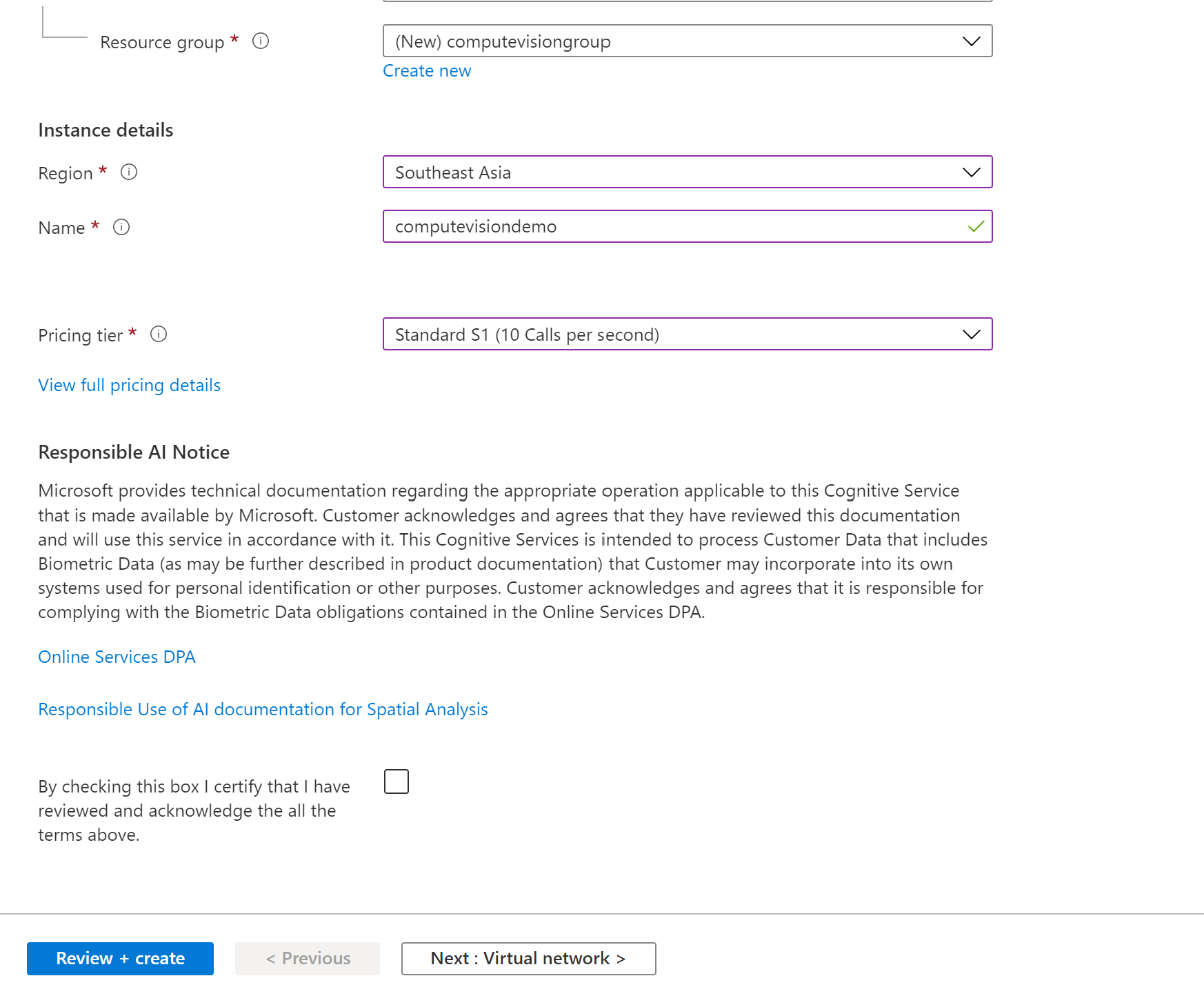
创建成功后,到资源的首页,选择Key and Endpoint, 记录下Key, Endpoint, region的信息。
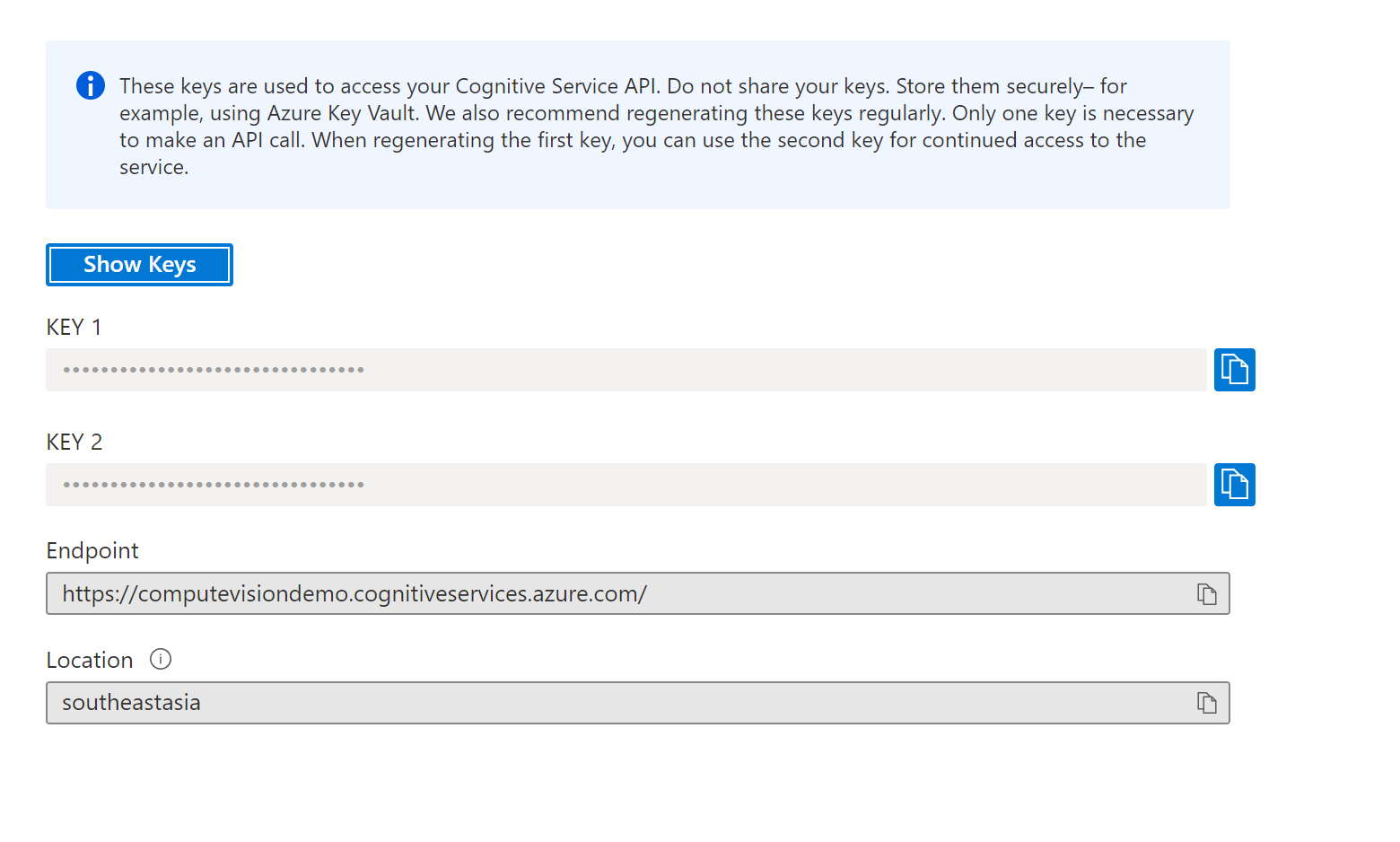
至此资源创建成功了。
创建测试程序
本节的demo代码可以在如下的位置找到:https://github.com/hylinux/azure-demo/tree/main/dotnet/cognitive-service/Vision/OCRDemo
我们使用.Net作为我们的测试工具,因此可以使用.Net 5提供的命令行工具来创建应用, 同时我们需要引用包Microsoft.Azure.CognitiveServices.Vision.ComputerVision
dotnet new console -n OCRDemo
cd OCRDemo
dotnet add package Microsoft.Azure.CognitiveServices.Vision.ComputerVision
编辑Program.cs, 添加如下的包引用
using System; using System.Collections.Generic; using Microsoft.Azure.CognitiveServices.Vision.ComputerVision; using Microsoft.Azure.CognitiveServices.Vision.ComputerVision.Models; using System.Threading.Tasks; using System.IO; using Newtonsoft.Json; using Newtonsoft.Json.Linq; using System.Threading; using System.Linq;
同时在类Program定义两个字段,引用上面已经保存的值key, endpoint
static string subscriptionKey = "PASTE_YOUR_COMPUTER_VISION_SUBSCRIPTION_KEY_HERE"; static string endpoint = "PASTE_YOUR_COMPUTER_VISION_ENDPOINT_HERE";
同时在相同的类中定义一个用于测试的图片
private const string READ_TEXT_URL_IMAGE = "https://intelligentkioskstore.blob.core.windows.net/visionapi/suggestedphotos/3.png";
该图片的显示效果如下
定义用于获取ComputeVisionClient对象,并认证的方法Authenticate
public static ComputerVisionClient Authenticate(string endpoint, string key) { ComputerVisionClient client = new ComputerVisionClient(new ApiKeyServiceClientCredentials(key)) { Endpoint = endpoint }; return client; }
这里有两个类需要说明一下:
| 类名 | 说明 |
|---|---|
| ComputerVisionClient | 所有计算机视觉功能都需要此类。 可以使用订阅信息实例化此类,然后使用它来执行大多数图像操作。 |
| ComputerVisionClientExtensions | 此类包含 ComputerVisionClient 的其他方法。 |
定义阅读图像的方法ReadFileUrl
public static async Task ReadFileUrl(ComputerVisionClient client, string urlFile) { Console.WriteLine("----------------------------------------------------------"); Console.WriteLine("READ FILE FROM URL"); Console.WriteLine(); //直接使用客户端从样例文件的URL把文件读入 //并进行识别 var textHeaders = await client.ReadAsync(urlFile); // After the request, get the operation location (operation ID) string operationLocation = textHeaders.OperationLocation; Console.WriteLine($"The Operation Location is {operationLocation}"); Thread.Sleep(2000); // Retrieve the URI where the extracted text will be stored from the Operation-Location header. // We only need the ID and not the full URL const int numberOfCharsInOperationId = 36; string operationId = operationLocation.Substring(operationLocation.Length - numberOfCharsInOperationId); // Extract the text ReadOperationResult results; Console.WriteLine($"Extracting text from URL file {Path.GetFileName(urlFile)}..."); Console.WriteLine(); do { results = await client.GetReadResultAsync(Guid.Parse(operationId)); } while ((results.Status == OperationStatusCodes.Running || results.Status == OperationStatusCodes.NotStarted)); // Display the found text. Console.WriteLine(); var textUrlFileResults = results.AnalyzeResult.ReadResults; foreach (ReadResult page in textUrlFileResults) { foreach (Line line in page.Lines) { Console.WriteLine(line.Text); } } Console.WriteLine(); }
在Main()方法中调用刚才定义的实例:
static async Task Main(string[] args) { var client = Authenticate(endpoint, subscriptionKey); await ReadFileUrl(client, READ_TEXT_URL_IMAGE); }
运行该实例:
dotnet run
运行结果如下:
C:\source\repos\azure-demo\dotnet\cognitive-service\Vision\OCRDemo>dotnet run
----------------------------------------------------------
READ FILE FROM URL
The Operation Location is https://computevisiondemo.cognitiveservices.azure.com/vision/v3.2/read/analyzeResults/2393d94f-d42d-42b9-b75c-fc37be28cbf5
Extracting text from URL file 3.png...
Nutrition Facts Amount Per Serving
Serving size: 1 bar (40g)
Serving Per Package: 4
Total Fat 13g
Saturated Fat 1.5g
Amount Per Serving
Trans Fat 0g
Calories 190
Cholesterol 0mg
ories from Fat 110
Sodium 20mg
nt Daily Values are based on Vitamin A 50%
calorie diet.
C:\source\repos\azure-demo\dotnet\cognitive-service\Vision\OCRDemo>
我们再次测试一个中文的图片例子:
测试的结果如下:
C:\source\repos\azure-demo\dotnet\cognitive-service\Vision\OCRDemo>dotnet run
----------------------------------------------------------
READ FILE FROM URL
The Operation Location is https://computevisiondemo.cognitiveservices.azure.com/vision/v3.2/read/analyzeResults/3610dff3-46c1-4ce7-828f-f2e0007d02c5
Extracting text from URL file u=252689820,3703174189&fm=26&gp=0.jpg...
方正风雅楷宋简体
方正风雅宋简体
方正细倩简体
方正清刻本悦宋简体
方正新秀麗緊體
方正是建德字体
方正剑体简体
汉仪平盛行简
默隔信愛手 写偉
非常的容易和简单,关于OCR的介绍就到这里了,有其他问题请和我联系哈。