五分钟快速的设置一个Standalone的Spark集群
分类: 开源和Linux技术 ◆ 标签: #Spark #Windows Subsystem for Linux ◆ 发布于: 2023-08-13 17:46:25

最近遇到一个非常棘手的问题,PowrBI Service通过Dataflow连接标准的Spark集群总是有问题会报错,为了重现并解决这个问题,我需要自己配置一个Spark的集群,之前一直使用的是Azure HDInsight Spark集群, 完全不用配置,但是Azure HDInsight Spark和标准的Spark集群完全是两回事,到最后仍然需要自己搭建一个Spark集群,我之前还记得我是如何在自己的机器上创建了8个虚拟机,使用这个8个虚拟机来配置hadoop的集群,如果这次仍然要使用hardoop以及Resource Manager来管理Spark的话, 我觉得我头都会大一圈,要花太多的时间了。仔细重新看了一下Spark的文档,Spark也支持standalone的模式运行,然后比较了一下spark运行在hadoop集群上和运行在standalone模式下对于应用来讲都是通过Thrift Server接入,这样看,Standalone的模式也是适用的。
研究了一下终于找到一个5分钟内搭建一个standalone模式运行的集群的方法,测试够用了。
您可以使用一个基于Ubuntu的虚拟机,更方便的是如果您的机器已经启用了WSL2, 那么就直接用WSL2吧,更快更方便。
启动终端并打开基于WSL2安装的Ubuntu, 先安装如下的必要的软件:
sudo apt update sudo apt install openjdk-11-jdk sudo apt install python3
然后完成之后,直接下载我们需要的spark软件包:
curl -O https://dlcdn.apache.org/spark/spark-3.4.1/spark-3.4.1-bin-hadoop3.tgz tar zxvf spark-3.4.1-bin-hadoop3.tgz sudo mv spark-3.4.1-bin-hadoop3 /opt/spark sudo chown -R {youruser}:{yourgroup} /opt/spark # 通常可以省掉这一步,但是防止你的文件的目录权限错误了
这样就将spark安装到了目录/opt/spark里了。
我们在用户主目录下要添加一些环境变量:
vim .bashrc
在文件最后添加如下的内容:
export SPARK_HOME=/opt/spark export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin
保存该问题件,然后让文件的配置生效:
source .bashrc
最后我们稍微设定一下spark master监听的地址就好了。
ghw@My-Games:~$ ifconfig eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.18.243.203 netmask 255.255.240.0 broadcast 172.18.255.255 inet6 fe80::215:5dff:fec6:9e7e prefixlen 64 scopeid 0x20<link> ether 00:15:5d:c6:9e:7e txqueuelen 1000 (Ethernet) RX packets 133 bytes 13378 (13.3 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 11 bytes 866 (866.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
记住wsl2的ip地址是:172.18.243.203
然后进入到目录/opt/spark/conf
cd /opt/spark/conf cp spark-env.sh.template spark-env.sh vim spark-env.sh
在文件的最后添加如下的内容:
SPARK_MASTER_HOST=172.18.243.203
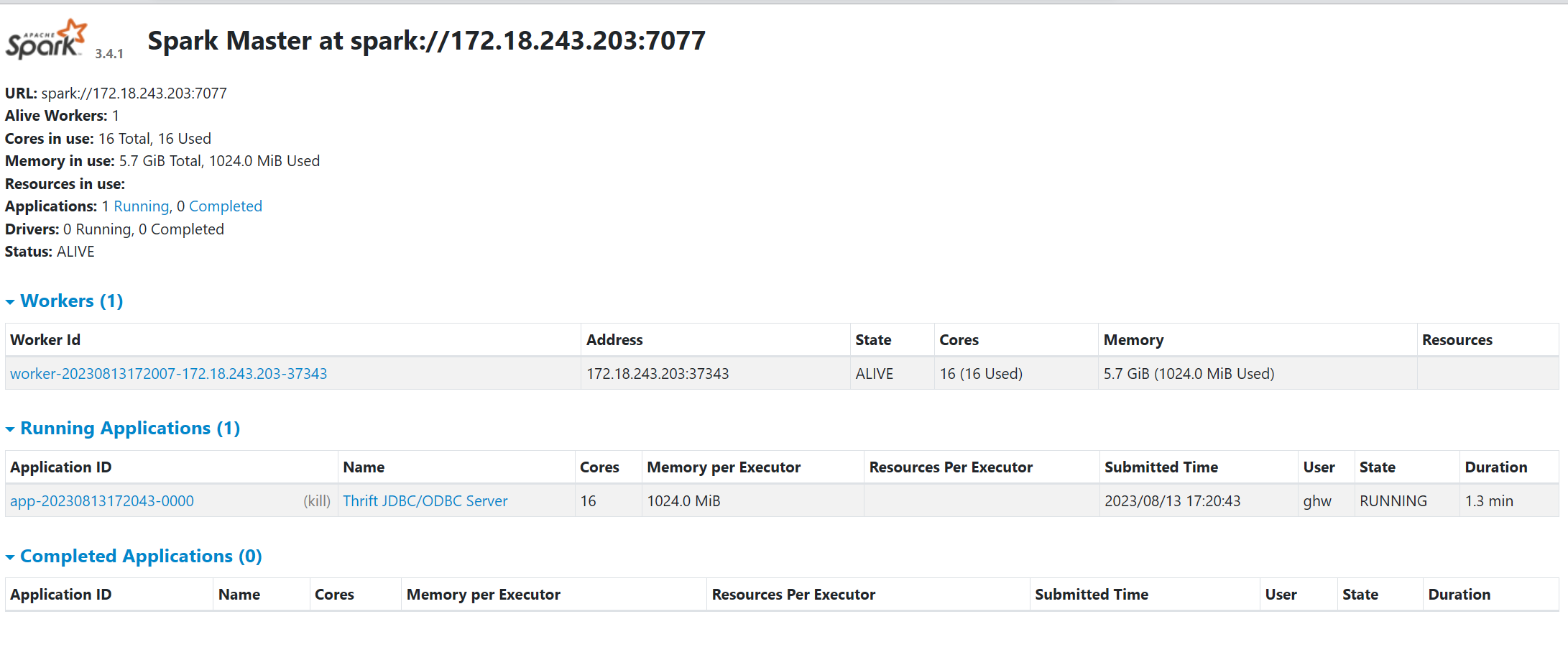
到这里就算是全部安装完成了。但是我们要使用这个集群的话,按照如下的方式启用:
start-master.sh #启动master
start-worker.sh spark://172.18.243.203:7077
start-thriftserver.sh --master spark://172.18.243.203:7077
这个时候使用浏览器打开:http://172.18.243.203:8080, 即可以看到集群的状态了。