自定义语音合成(Custom Voice)介绍
分类: Azure认知服务 ◆ 标签: #Azure #人工智能 #语音服务 ◆ 发布于: 2023-06-05 17:26:41

我们前面一章介绍了什么Custom Speech和Azure提供的工具Speech Studio, 我们先回顾一下:实际上Azure通过提供工具Speech studio来帮助大家定制化自己的语音识别、语音合成、以及另外一个非常强大的工具有声内容生成器, 同时我们需要理解自定义语音识别或者自定义语音合成的基本步骤都是:
- 准备用于训练的基础数据
- 用
Speech studio提供的工具使用你准备好的数据进行新模型的训练 - 模型训练结束后,准备用于测试的数据,对于训练好的模型进行精度测试。
- 测试符合要求之后,使用自定义模型提供的endpoint,结合SDK或者rest api整合到您的应用中去。
我们在前一章已经向大家描述了speech studio这个工具的基本使用方法和界面介绍,这个工具使用起来及其直观,开盒即用,无需过多的成本,如果大家想了解一下这部分的内容,请到上一章回顾一下。
我们上一章讲述了如何自定义语音识别,本章介绍一下如何自定义语音合成。重点在于如何准备用于训练模型的数据。语音识别我们用于训练的数据包括两种:
- 语音 + 脚本
- 相关性文本
需要注意的是在语音合成中我们采用的训练方法是采用了神经网络训练的模型,从该技术上大致的讲在这个部分中分了三个部分:
- 文本分析器
- 基于神经网络的声学模型
- 基于神经网络的语音编码器
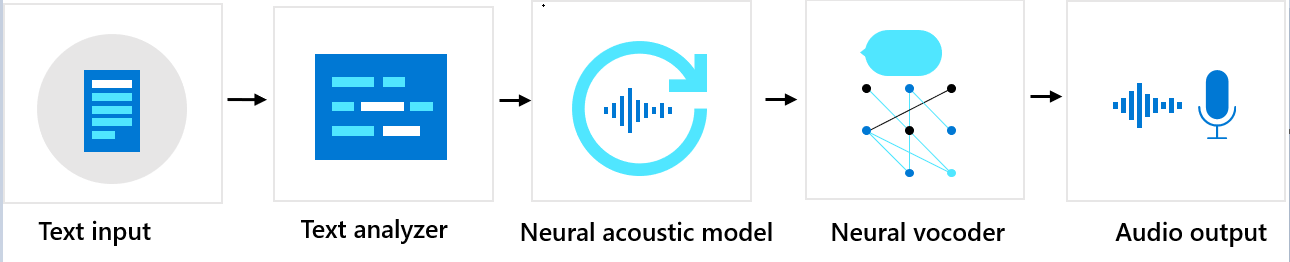
一段文本到实际的语音合成的基本流程是:用户输入的文本进入文本分析器,通过文本分析器分析后,输出一系列的基本的音素(关于什么是音素,大家需要额外的找相关的理论文档看一下,简要的解释就是音素指的是语言中能够划分最小单位的语音单位,包括基本的单词,单词发音等等), 这些音素系列输出之后,再输入到基于神经网络的声学模型,该模型使用预定义的模型对这些音素系列进行配置,主要配置例如音调,情感,速度等等,最终我们会使用基于神经网络的语音编码器合成需要的声学文件。整个流程可以使用如下的图大致的描述一下:
如何开始训练自己的声音合成模型
你需要一个Azure的订阅,有了该订阅之后,你需要创建一个Speech服务,创建完成之后,通过如下的地址登录到Speech StudioPortal中,然后使用该工具提供的工具就可以了。
准备训练的数据
数据的类型可以有三种格式,比较推荐用第一种。
声音文件 + 脚本
在开始训练之前,需要注意一个安全和许可的问题,微软要求在准备的数据中必须要包含一个配音人员的个人资料以及授权书。形式上必须和你准备的培训数据是一致的。最为常用的数据格式是一个录音文件对应脚本里的一句翻译(脚本的内容就是你录音路的讲话内容), 例如在目录c:\yourdata下有很多多个录音文件,这些录音文件的文件名类似:001.wav, 002.wav, 003.wav等等。然后你脚本文件里内容类似这样的:
格式是:001[Tab]录音内容
001 你今天去哪里了? 002 每天的计划是什么? 003 我今天干什么了?
因为每个录音文件不能超过15秒,很容易使用一个脚本将所有的内容都准备好。最方便的做法是先准备好脚本文件,然后按照脚本文件进行录制,就可以了。
另外配音员的声明文件使用另外一个声音文件,并配上脚本,需要注意的是声明的文件的内容是有要求的,必须包括如下的内容:
"我[说出你的名字和姓氏]知道,[说出公司名称]将使用我的声音录音来创建和使用我的声音的合成版本。"
这句话的内容必须和客户准备的数据打包成一个zip文件,并在Speech Studio里进行上传,然后训练您的模型。
长音频文件 + 脚本
我们前面使用的短的音频文件(不超过15秒) + 脚本来准备数据,我们也可以使用比较长的音频文件和脚本来训练,但是需要注意的是长音频文件依赖服务Speech to text服务,因此需要注意这部分第一要求定价层必须在标准层,另外收费也是不一样的,因为还使用了speech to text的服务。同时这个功能目前还是预览版,长音频文件可以长于20秒,但是总的打包文件不能超过2个G, 其他和第一个没有什么区别,同样也需要准别声明文件。
仅仅只有音频文件
目前这个还在测试版,顾名思义,一般情况还是建议使用第一种数据,准备起来并不麻烦。
数据准备好了之后,需要使用speech studio进行训练训练即可,训练结束后,即可以使用自定义的模型了。