自定义语音识别(Custom Speech)指南
分类: Azure认知服务 ◆ 标签: #Azure #人工智能 #语音服务 ◆ 发布于: 2023-06-05 17:23:31

前面的文章我们学习了如何通过SDK进行语音识别(Speech-to-text), 默认情况下我们使用的是由微软训练出来的基础模型或者是基于基础模型上升级并发布的模型,对于大多数的场景,这些由微软提供的模型可以工作得不错,但是有时候可能需要让这些模型更加适合某些特殊得行业或者适合某些特殊的环境,例如你所处的行业有很多专有的专业名词等等,或者你发现在使用微软提供的模型发现语音识别的精度没有达到要求,那么您可以通过微软提供的工具Speech Studio来训练适合自己的模型,测试和评估该模型之后,如果达到了精度要求,那么久可以通过Speech Studio这个工具进行部署, 自己的系统直接使用自定义的模型,从而达到业务精度的需要。
本节我们分成如下几个部分来介绍:
- 自定义语音识别的一般流程。
- 需要准备的数据以及准备数据的基本原则和格式要求。
- 如何进行模型测试,评估以及训练新模型以及发布自定义的模型。
自定义语音识别的一般流程
前面我已经讨论过了,我们需要使用微软提供的工具Speech Studio来完成自定义语音识别的工作 我们简要的介绍一下这个工具。
Speech Stdio简介
Speech Studio根据Azure部署的区域不同,可以从不同的网址来访问: Speech for Azure Global, Speech for Azure China, 用户可以根据自己的订阅所在的区域选择不同地址的工具,工具使用上是一致的。
注意
使用Speech Studio工具要求你有Azure的订阅,并且也已经创建了一个Azure Speech服务。另外通过Speech Studio进行自定义不支持F0定价层(F0定价层是免费定价层), 必须要有S0的定价层。
点击上述的网址之后,根据提示登录到Speech Studio, 然后选择创建好的Azure Speech服务,点击左上角的转到Speech Studio, 进入了Speech Studio Portal, 如下图:
从Speech Studio Portal可以看到当前,支持不少自定义服务,包括我们看到的自定义语音识别, 自定义语音合成以及有声内容创作, 本节我们需要创建自定义语音识别, 点击该选项之后,即出现你项目列表:
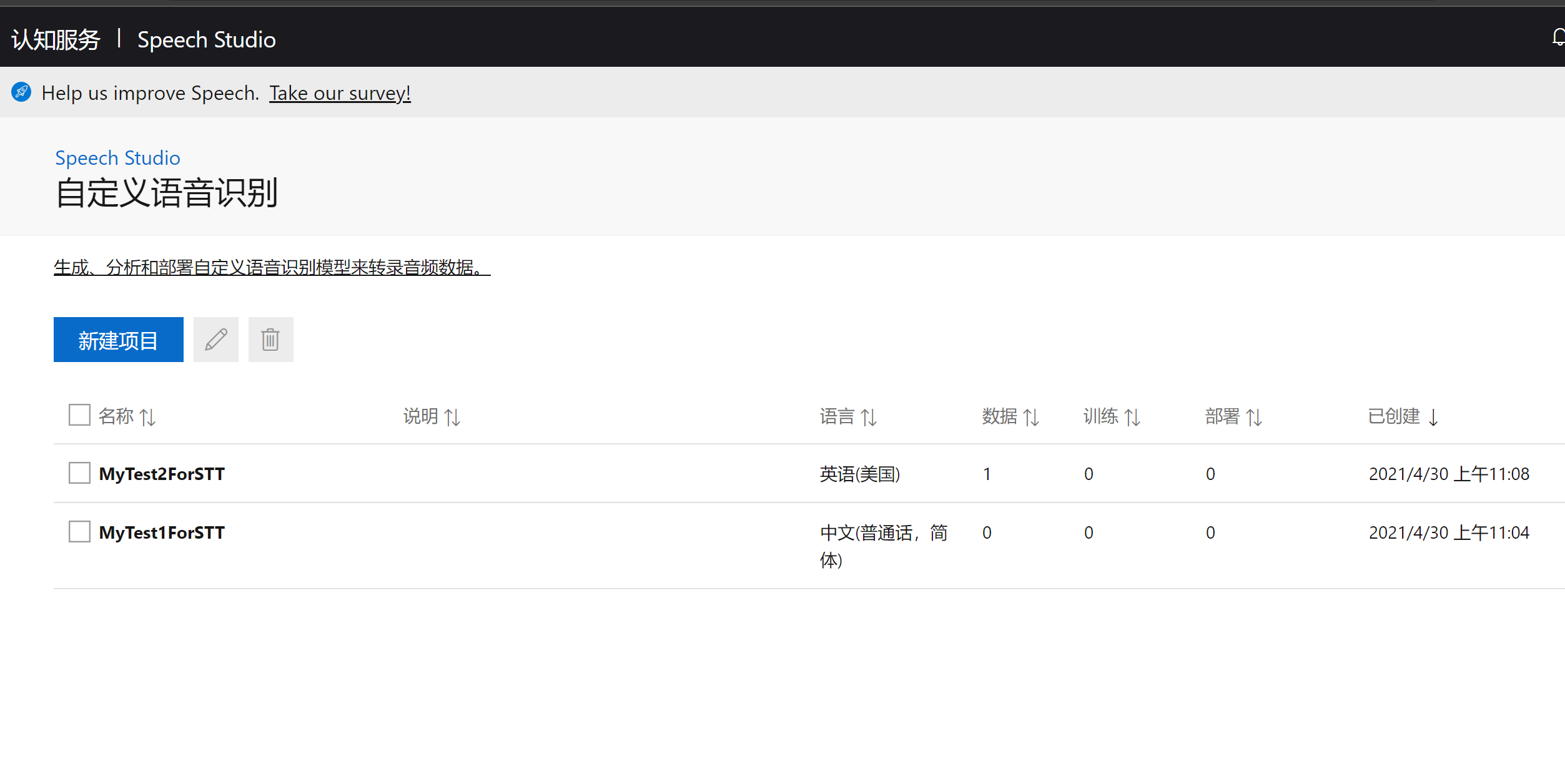
点击新建项目, 即出现创建新项目的界面:
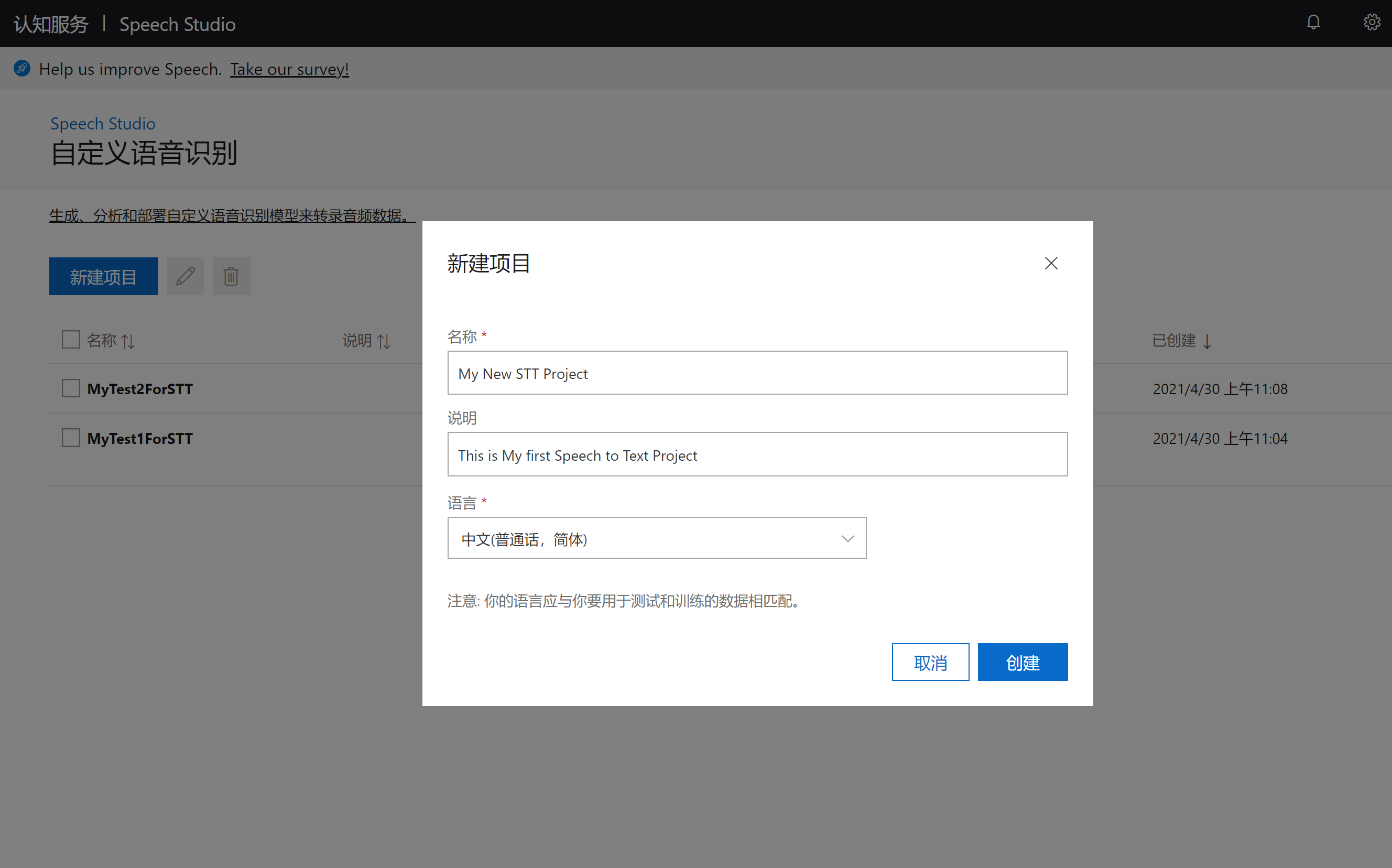
如上图,填写自己的项目名,以及项目描述,同时需要注意的是选择自己想自定义项目的语言,例如简体中文, 填写好了之后,然后选择创建,会自动转入到新创建的项目:
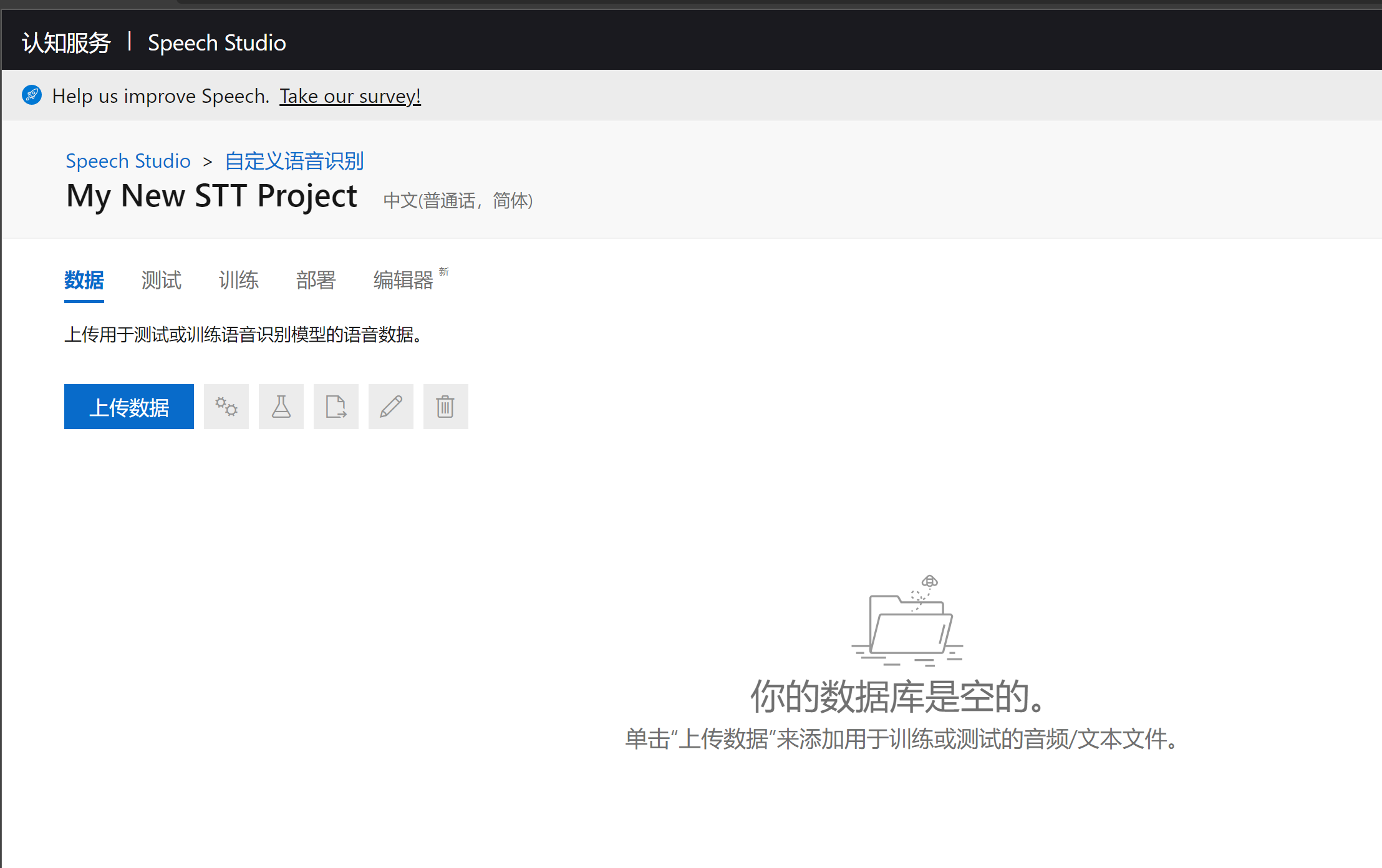
从项目的首页可以看到工具里有数据、测试、训练、部署、编辑器几个部分, 这里几个Tab分别对应了我们在自定义语音识别的基本步骤。
自定义语音识别的一般步骤描述
当我们在使用模型完成我们的业务的时候,你可以使用测试数据对模型的精度进行测试(使用测试Tab), 如果发现精度不够,那么准备数据,然后进行模型训练,模型训练结束了之后,可以将自定义的模型部署好,部署成功后,用户的代码即可以使用部署好的自定义的模型终结点。下图可以描述一般性的步骤:
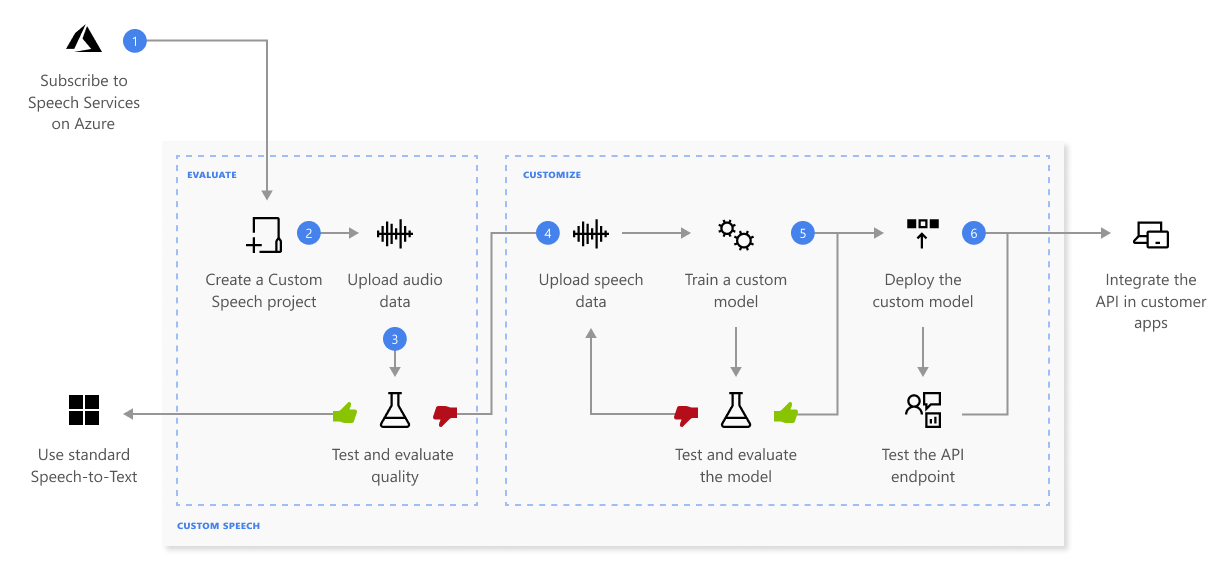
准备数据
在准备数据之前我们先理解一下,我们有哪些数据需要准备,每种数据适用什么业务。
- 音频数据(仅有音频数据), 主要用户测试模型的准确度,用于测试目的。建议最少5个音频文件用于测试。
- 音频数据+音频脚本, 可以同时用于测试评估和训练模型。 所有的音频文件建议0.5 - 5 个小时之间(用于测试,评估或者训练自定义模型)
- 相关性文本,只是文本文件,只能用于训练模型。
音频数据
我们前面定义了,仅有音频数据的话,主要是用于测试和评估模型的,同时默认是支持16khz 单声道的wav文件,如果你有其他格式可以通过工具Sox来转换。SoX的地址是:(http://sox.sourceforge.net/), 用法如下:
转化音频格式
sox <input> -b 16 -e signed-integer -c 1 -r 16k -t wav <output>.wav
检查音频格式:
sox --i <filename>
准备好音频数据文件之后,需要压缩成zip文件,然后上传即可。
音频文件 + 音频脚本
音频文件和之前的音频文件是一直的,但是一个zip中可以有多个音频文件,和一个脚本文件,在脚本文件里,每一行第一列都是文件名,后面以tab分割是音频内容的文字。
例如:
speech01.wav speech recognition is awesome speech02.wav the quick brown fox jumped all over the place speech03.wav the lazy dog was not amused
然后目录结果如下:
![]()
然后打包成zip文件就可以了。
相关性文本
相关性文本顾名思义主要是为了解决现有的模型无法正确识别特定场景或者是特定行业的专用名词或者特定的发音等等问题。同时相关性文本可以区分为两种一种是特定的短语或者句子,另外一种是特定发音。
- 特定的短语或者句子: year, month, machine等等。
- 特定发音: 例如:3CPO three c p o, CNTK c n t k, IEEE i triple e
测试和训练模型
数据准备之后,将数据上传到Speech studio, 然后可以直接使用该工具进行测试和训练。Speech Studio是一个很简单的工具,按照提示进行就可以了。
自定义语音识别介绍就到这里结束,更详细的文档,您也可以参考文档: (https://docs.microsoft.com/zh-cn/azure/cognitive-services/speech-service/custom-speech-overview)