Azure Databricks入门 - 认识一下Databricks的数据对象
分类: Azure Databricks ◆ 标签: #基础 #Azure #大数据 #入门 ◆ 发布于: 2023-08-07 20:46:28

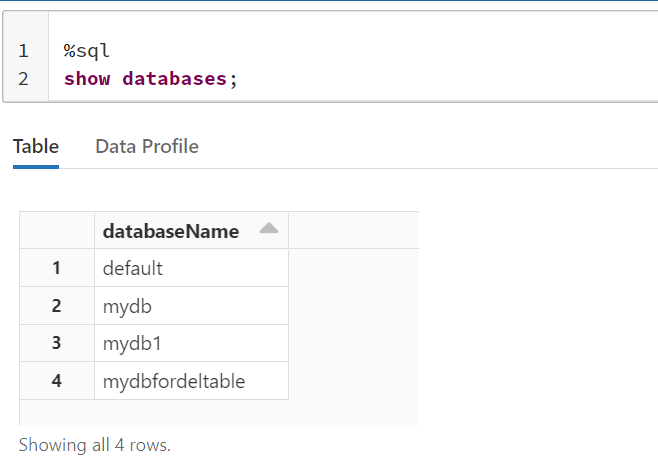
我在已经启动的Azure Databricks上创建了一个基于SQL的notebook, 然后尝试运行如下的语句:
show databases;
返回如下的结果:
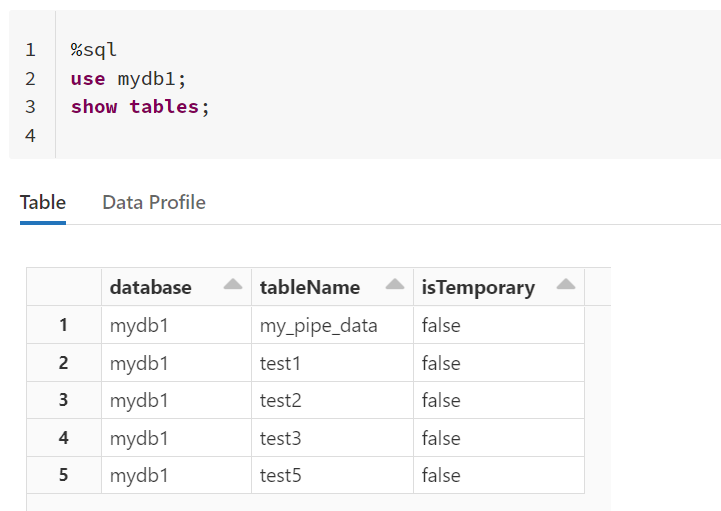
然后我继续运行SQL命令:
%sql use mydb1; show tables;
返回如下的结果:
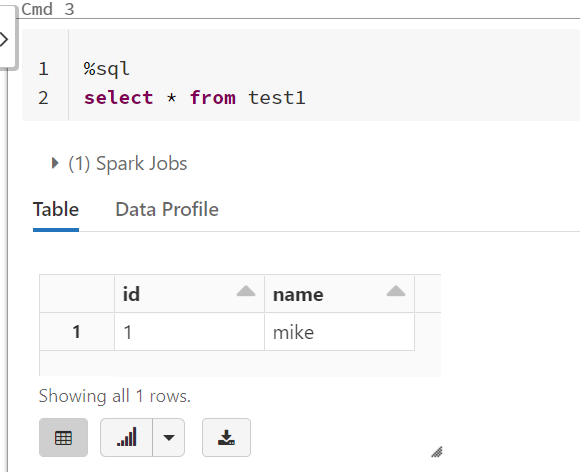
我们继续运行如下的sql:
select * from test;
虽然这些命令都很简单,但是同时带来了一系列的问题:
- 这些数据库到底是什么数据库?是关系型数据库吗?
- 这些表是什么类型的表?
首先这些肯定不是关系数据库,虽然他们看起来非常像,在Databricks中数据库仅仅是其中用于组织数据对象的一个形式,数据库代表的是数据表的集合。
另外我们学习过关系型数据或者其他的no sql数据库也好,都有元数据的概念,那么databricks用于存储元数据的服务是什么?
- Unity Catalog: 是下一代由
databricks开发的元数据管理服务,目前还是在public preview,还不能用于正式生产,而且Azure China也不支持。这个服务将数据对象分为三个级别:catalog.database.table。 hive metastore: 目前应用成熟的元数据服务,直接使用了Hive的服务。在Databricks中,每个集群的节点上都会安装一个Hive metastore的客户端,这些客户端都会链接到Control panel的Hive Meta store服务上,在Azure Databricks中,后端默认是Azure Database for MySQL。
默认情况下Databricks是直接使用hive metastore服务的,因此你可以尝试运行下述的语句:
select * from hive_metastore.mydb1.test1
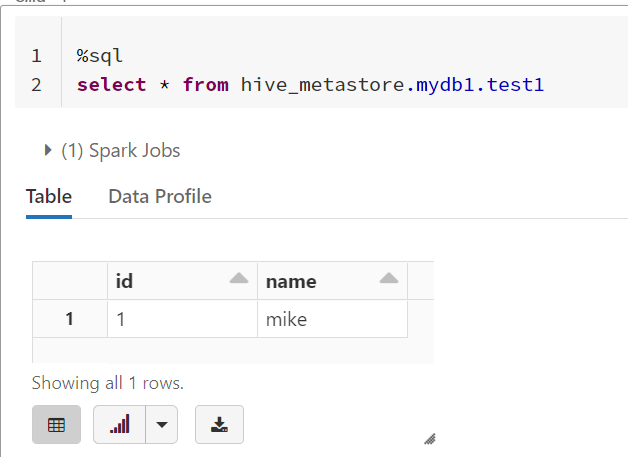
也说明在使用hive metastore的情况,统一的catelog就是hive_metastore
默认的表类型
我们前面已经学习了默认的meta store是hive metastore, 那么默认的表类型是什么类型呢?
默认的表类型是Delta table类型, 至于什么是Delta table, 我们后面再来学习。简单说它是基于PARQUET数据格式的一种新的数据类型。
如果在databricks里创建一个表,而不指定数据源,那么它的表类型默认就是Delta table。
同时Databricks支持很多种类型数据源的表,例如支持:
CSVHive TablePARQUET
等等。
我们可以用一系列的语句来验证:
%sql CREATE DATABASE mydbtest LOCATION '/mnt/{your network filesystem}/mydbtest'
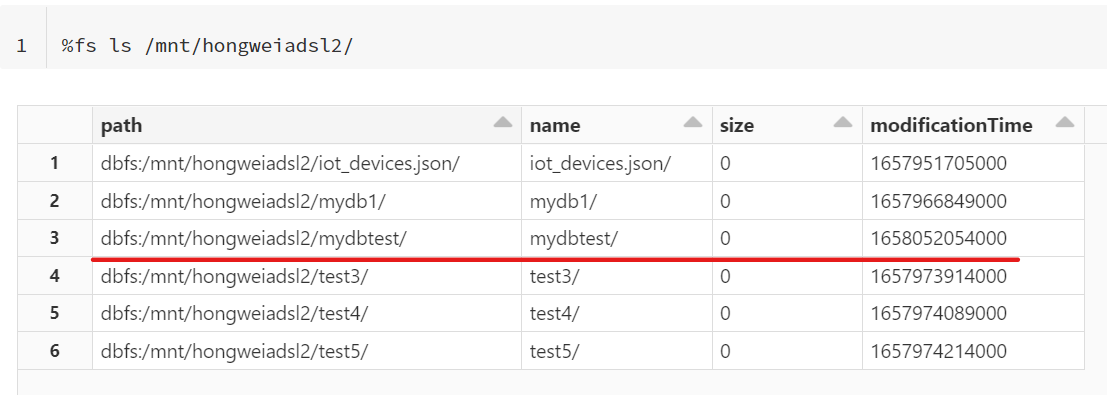
然后查看你刚刚创建的目录:
%fs ls /mnt/{your network filesystem}/mydbtest
然后我们再创建一个表, 并拷贝数据:
USE mydbtest; CREATE TABLE IF NOT EXISTS loan_risks; COPY INTO loan_risks FROM '/databricks-datasets/learning-spark-v2/loans/loan-risks.snappy.parquet' FILEFORMAT = PARQUET FORMAT_OPTIONS ( 'mergeSchema' = 'true') COPY_OPTIONS ('mergeSchema' = 'true'); SELECT * FROM loan_risks limit 5;
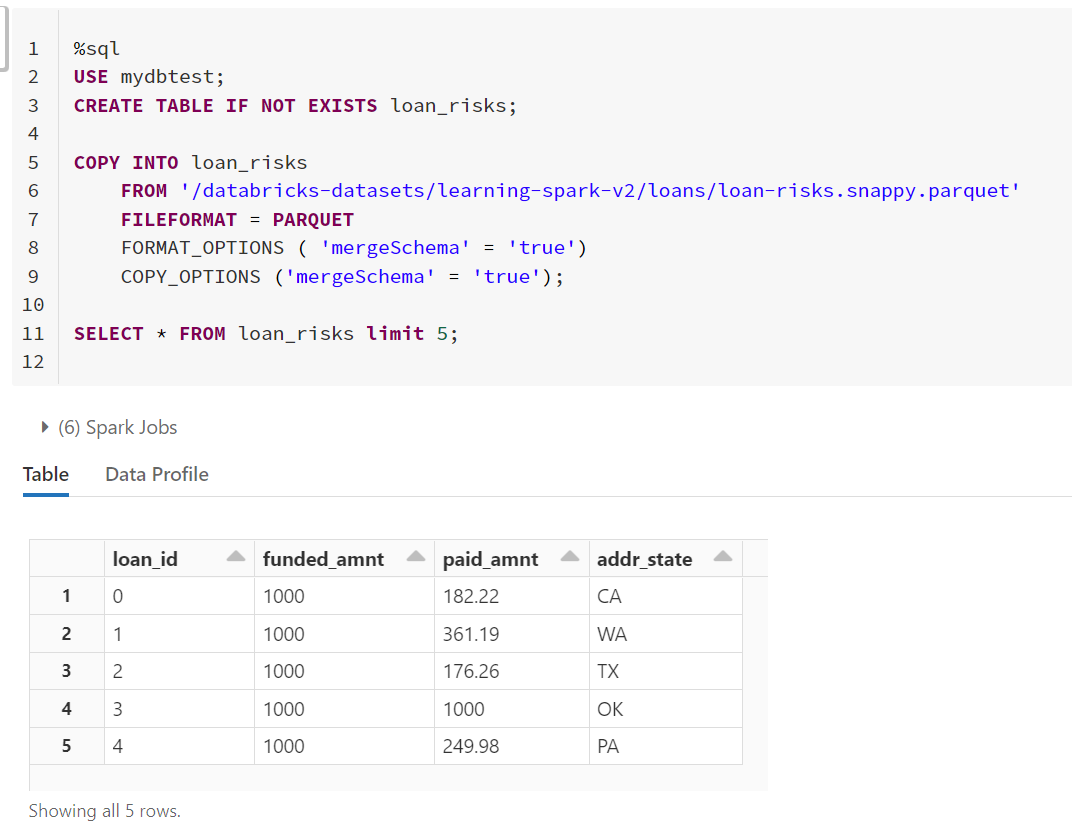
由于我们在创建时并没有指定表的格式,因此默认就是Delta表。
可以查看文件明确一下:
%fs ls /mnt/hongweiadsl2/mydbtest/loan_risks
结果如下图:

同时你可能已经注意到了,我们在使用COPY INTO时可以选择多种数据源,注意区分表类型和数据源。
我们可以这样测试一下,假设我们想要一个纯粹PARQUET的表呢?
%sh mkdir /dbfs/mnt/hongweiadsl2/mydbtest/test1 cp /dbfs/databricks-datasets/learning-spark-v2/loans/loan-risks.snappy.parquet /dbfs/mnt/hongweiadsl2/mydbtest/test1 ls /dbfs/mnt/hongweiadsl2/mydbtest/test1
这样我们来创建一个基于PARQUET的表
%sql %sql CREATE TABLE IF NOT EXISTS test1 ( loan_id BIGINT, funded_amnt INT, paid_amnt DOUBLE, addr_state STRING ) USING PARQUET LOCATION '/mnt/hongweiadsl2/mytest/test1/';
这样就可以创建一个基于PARQUET的表了。
同样也可以创建一个基于hive的表,只需要使用语句USING HIVE 即可以为一个hive格式的表。
Managed表和外部表
Databricks管理的表和外部表概念和Hive的内部表以及外部表的概念是一致的。managed表由databricks管理元数据和数据,但是外部表databricks仅仅管理元数据,就不过多的描述了。