Azure Databricks Job/notebook运行卡住三板斧 之一 重启大法好
分类: Azure Databricks ◆ 标签: #Azure #Databricks ◆ 发布于: 2023-06-15 21:22:46

最近遇到不少用户运行的job/notebook卡住的情况,特地将解决该类型问题的三板斧记录下来。
板斧一
如果用户有在集群上安装额外的library, 特别是在Azure China通过官方的源安装Python包,Jar包(通过Maven), 有较大机率遇到类似的问题,是由于国内机房某些时候访问这些境外的源会遇到无法访问或者下载速度缓慢的原因,这个问题非常容易重现,重现步骤如下:
- 创建一个集群,并启动。
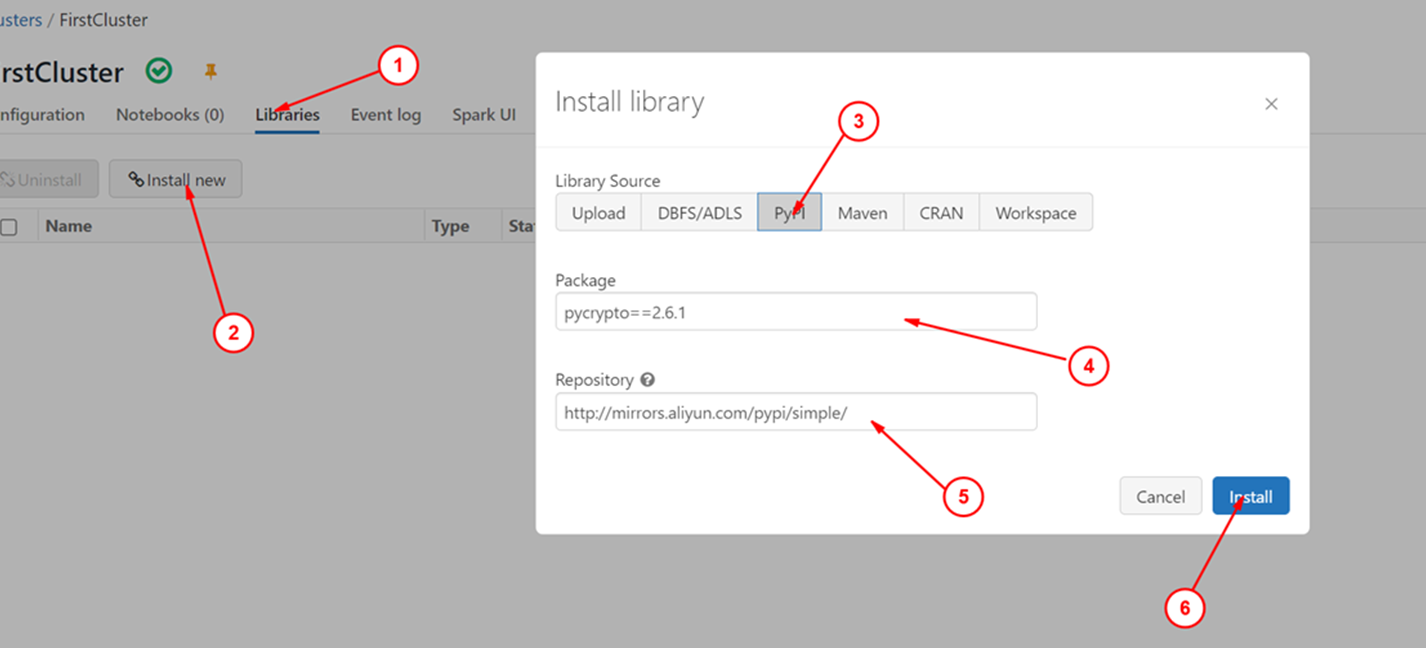
- 进入
workspace->Compute, 选择已经启动并创建的集群,然后在Library栏中选择Install New - 选择
Pypi, 输入一个包名,Repository选择一个不能访问的地址,因为我们这里是为了重现问题。 - 点击
install
整个步骤如下图所示:
然后打开一个notebook, 随意写一些语句,运行,然后就可以重现该问题了,可以看到运行的notebook会一直被卡住:
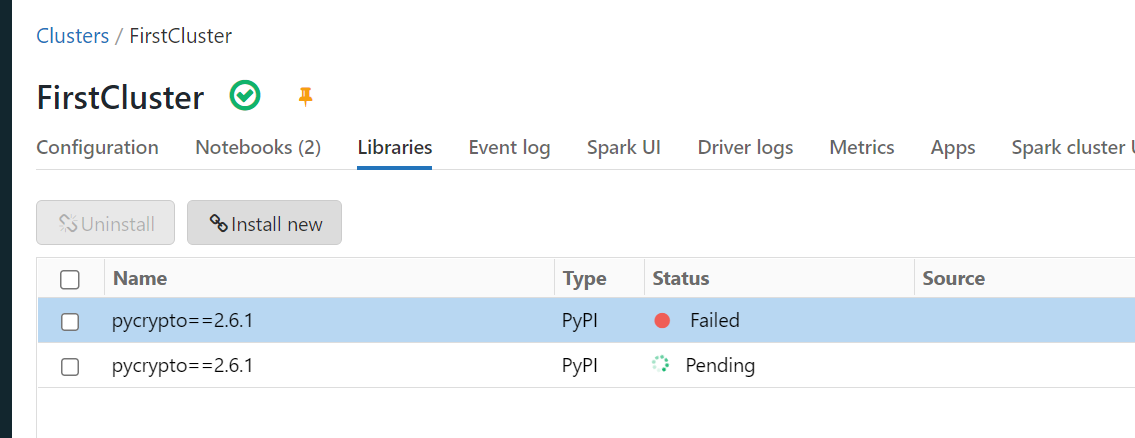
Notebook 被卡住了
类似这样的问题,最好的缓解办法是先在集群的Spark UI里将卡住的job 杀掉。然后重新配置一下国内的源,例如上述图中,在Repository 里输入国内的源,就可以缓解这个问题。
注意经过测试阿里源http://mirrors.aliyun.com/pypi/simple不可用。
板斧多一点
刚刚上面是讨论了常见的job/notebook 被卡住特别常见的原因,不过重启还是要再说一下,重启的步骤如下:
- 进入workspace, 选择你的集群:
- 选择
Spark UI, 默认就是Job页,选择被卡住的Job, 单击Description中的kill即可杀死所有的job/noteboo - 重启集群重试。
再多一点
建议使用Job Cluster来运行job, 而不要用非交互式集群来运行。
更多一点
实际上从用户提供的driver log可以追溯到很多类似的异常:
ERROR: Could not find a version that satisfies the requirement pycrypto==2.6.1 ERROR: No matching distribution found for pycrypto==2.6.1 at org.apache.spark.util.Utils$.executeAndGetOutput(Utils.scala:1535) at org.apache.spark.util.Utils$.installLibrary(Utils.scala:963) at org.apache.spark.executor.Executor.$anonfun$updateDependencies$4(Executor.scala:1299) at scala.collection.TraversableLike$WithFilter.$anonfun$foreach$1(TraversableLike.scala:877) at scala.collection.immutable.RedBlackTree$._foreach(RedBlackTree.scala:103) at scala.collection.immutable.RedBlackTree$._foreach(RedBlackTree.scala:102) at scala.collection.immutable.RedBlackTree$.foreach(RedBlackTree.scala:99) at scala.collection.immutable.TreeMap.foreach(TreeMap.scala:205) at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:876) at org.apache.spark.executor.Executor.updateDependencies(Executor.scala:1287) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:745) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:672) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Driver stacktrace: at com.google.common.util.concurrent.AbstractFuture$Sync.getValue(AbstractFuture.java:299) at com.google.common.util.concurrent.AbstractFuture$Sync.get(AbstractFuture.java:286) at com.google.common.util.concurrent.AbstractFuture.get(AbstractFuture.java:116) at com.google.common.util.concurrent.Uninterruptibles.getUninterruptibly(Uninterruptibles.java:135) at com.google.common.cache.LocalCache$LoadingValueReference.waitForValue(LocalCache.java:3552) at com.google.common.cache.LocalCache$Segment.waitForLoadingValue(LocalCache.java:2298) at com.google.common.cache.LocalCache$Segment.get(LocalCache.java:2187) at com.google.c---------------------------------------------------------------------------
这样更有助于确认就是安装包的问题。