Azure认知搜索学习之使用Portal快速入门 - 添加AI技能组
分类: Azure搜索 ◆ 标签: #Azure #Search #认知搜索 ◆ 发布于: 2023-06-12 20:43:17

本快速入门演示了Portal中的AI技能组合支持,介绍如何使用光学字符识别(OCR)和实体识别从图像和应用程序文件创建可搜索的文本内容。
我们预先要创建几个资源,并上传示例图像和应用程序内容文件。 一切准备就绪后,可在 Azure 门户中运行import data向导,以将这些数据提取到一起。 最终结果是一个可在门户(搜索资源管理器)中查询的可搜索索引,其中填充了 AI 处理功能创建的数据。
开始之前,必须具备以下先决条件:
- 具有活动订阅的 Azure 帐户。
- Azure 认知搜索服务。 创建服务或在当前订阅下查找现有服务。 可以使用本快速入门的免费服务。
- 具有 Blob 存储的 Azure 存储帐户。
备注
此快速入门还将认知服务用于 AI。 由于工作负荷很小,因此,认知服务在幕后会抽调一部分算力来免费处理事务(最多 20 个)。 这意味着,无需创建其他认知服务资源即可完成此练习。
设置数据
在以下步骤中,在 Azure 存储中设置 blob 容器以存储异类内容文件。
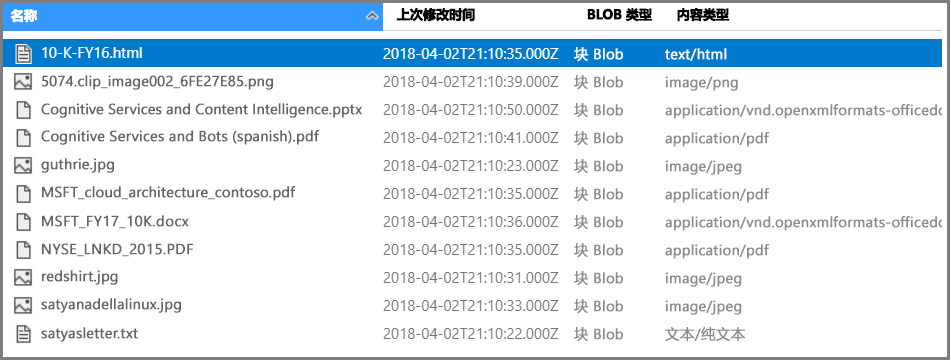
下载示例数据:https://1drv.ms/f/s!As7Oy81M_gVPa-LCb5lC_3hbS-4,其中包括不同类型的小型文件集。 解压缩文件。
创建 Azure 存储帐户或查找现有帐户。
- 选择 Azure 认知搜索所在的同一区域,以避免带宽费用。
- 选择StorageV2(常规用途 V2)。
打开 Blob 服务页并创建一个容器。 可以使用默认的公共访问级别。
在容器中,单击“上传”以上传在第一个步骤中下载的示例文件。 请注意,内容类型非常广泛,其中包括图像和应用程序文件,而这些内容在使用其本机格式时不支持全文搜索。
现在可以在“导入数据”向导中转到下一步。
运行Data import向导
- 使用 Azure 帐户登录到 Azure 门户。
- 查找搜索服务,并在“概述”页中,单击命令栏上的“导入数据”,通过四个步骤设置认知扩充。|

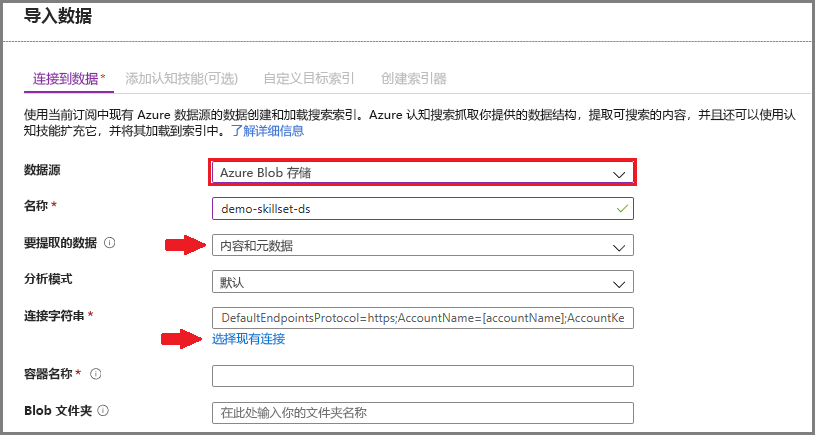
步骤 1 - 创建数据源
- 在“连接到数据”中选择“Azure Blob 存储”,然后选择创建的存储帐户和容器 。 为数据源命名,并对余下的设置使用默认值。
继续转到下一页。
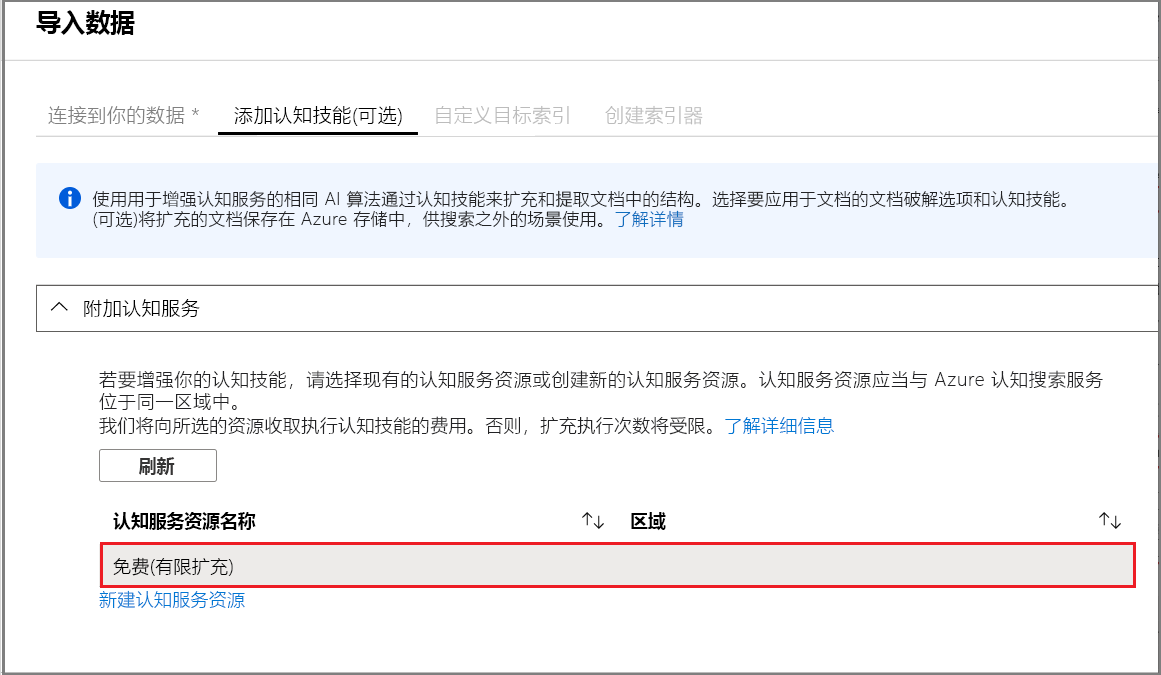
步骤 2 - 添加认知技能
接下来,配置 AI 扩充来调用 OCR、图像分析和自然语言处理。
本快速入门将使用 免费 的认知服务资源。 示例数据包括 14 个文件,因此,认知服务免费提供的 20 个事务配额足以完成本快速入门。
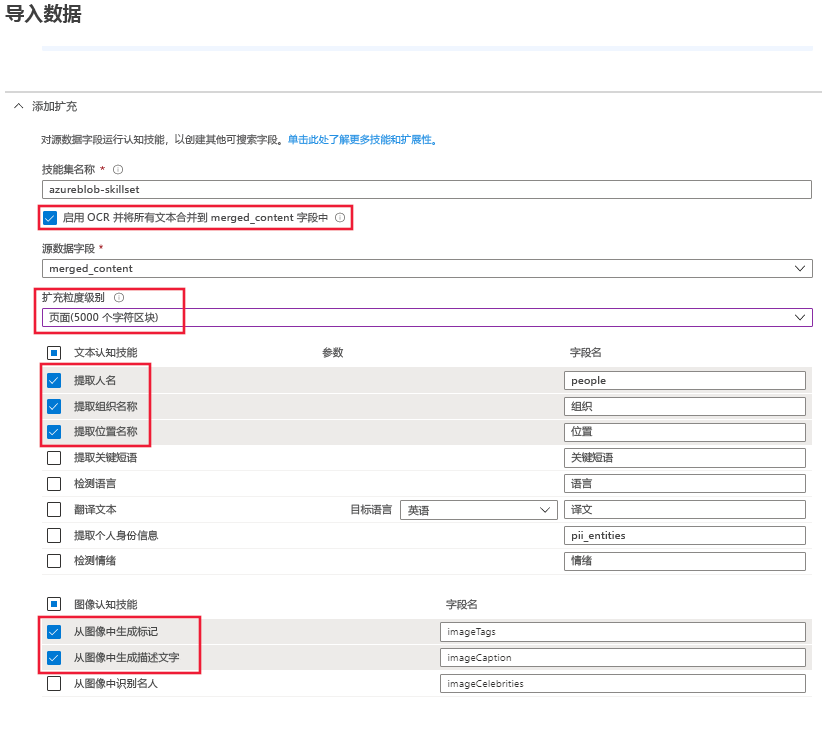
展开“添加扩充”,进行四个选择。
展开“添加扩充”,进行四个选择。
启用 OCR,将图像分析技能添加到向导页。
将“粒度”设置为“页面”,以将文本拆分为较小的区块。 几种文本技能仅限 5 KB 输入。
选择实体识别(人员、组织和位置)和图像分析技能。
继续转到下一页。
步骤 3 - 配置索引
索引包含可搜索的内容,import data向导通常可以通过对数据源采样来创建架构。 在此步骤中查看生成的架构,并根据情况修改任何设置。 以下是为演示 Blob 数据集创建的默认架构。
在本快速入门中,向导能够很好地设置合理的默认值:
- 默认字段基于现有 blob 的属性以及包含扩充输出的新字段(例如 people、organizations、locations)。 数据类型从元数据和数据采样推断。
- 默认文档键是 metadata_storage_path(由于字段包含唯一值,因此选择了此键)。
- 默认属性为 可检索 和 可搜索。 可搜索 允许对字段进行全文搜索。 可检索 意味着可以在结果中返回字段值。 向导假设你希望这些字段可检索且可搜索,因为它们是通过技能集创建的。
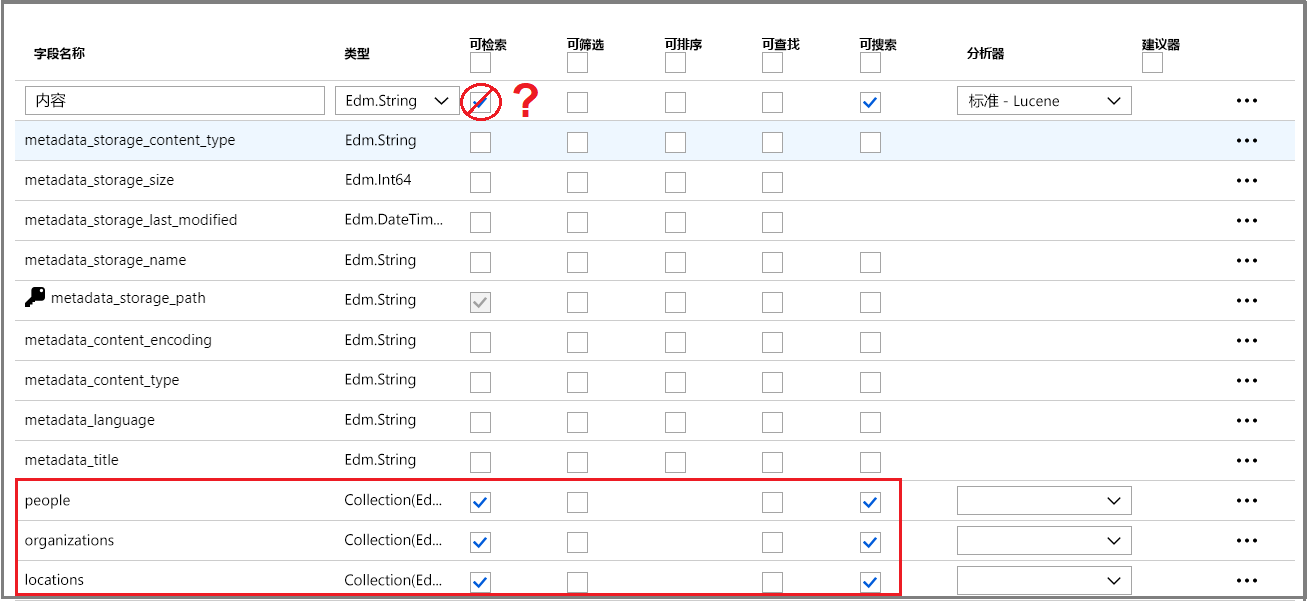
请注意 content 字段旁边的 Retrievable 属性带有删除线和问号。 对于包含大量的文本的 Blob 文档,content 字段包含文件主体,因此可能包含数千行。 此类字段在搜索结果中不实用,应在此演示中排除它。
但是,如果需要将文件内容传递到客户端代码,请确保可检索保持选定状态,以便允许搜索引擎返回该字段。
将某个字段标记为 Retrievable 并不意味着该字段一定会出现在搜索结果中。 可以使用 $select 查询参数指定要包含的字段,来精确控制搜索结果的构成。 对于包含大量文本的字段(例如 content),可以使用 $select 参数针对应用程序的用户整理可管理的搜索结果,同时确保客户端代码可以通过 Retrievable 属性访问全部所需信息。
继续转到下一页。
步骤 4 - 配置索引器
索引器是推动索引过程的高级资源。 它指定数据源名称、目标索引和执行频率。 “导入数据”向导将创建多个对象,其中始终包括一个可以重复运行的索引器。
- 在“索引器”页中,可以接受默认名称并单击“一次”计划选项来立即运行该索引器 。
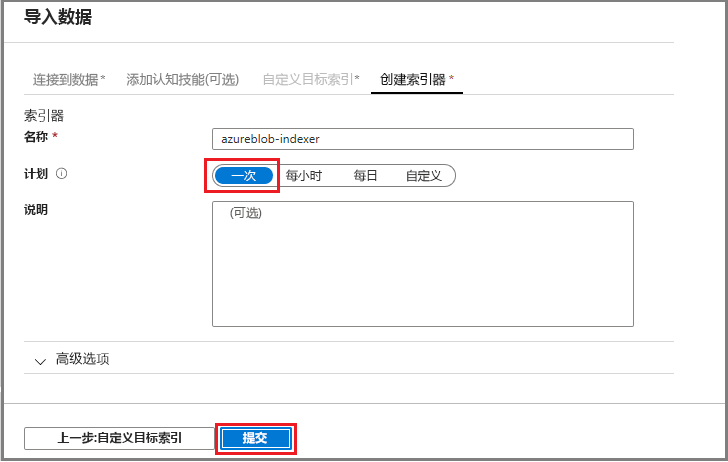
- 单击“提交”以创建并同时运行索引器。
监视状态
与典型的基于文本的索引相比,认知技能索引编制需要花费更长的时间才能完成,OCR 和图像分析尤其如此。 若要监视进度,请转到“概述”页,然后单击页面中间的“索引器”。

由于内容类型广泛,因此警告很常见。 某些内容类型对于特定技能并不有效,在较低层级上,常常会遇到索引器限制。 例如,32,000 字符的截断通知是“免费”层级上的索引器限制。 如果在更高的层级上运行此演示,许多截断警告会消失。
若要检查警告或错误,请在“索引器”列表中单击“警告”状态以打开“执行历史记录”页。
在该页上再次单击“警告”状态以查看警告列表,如下所示。
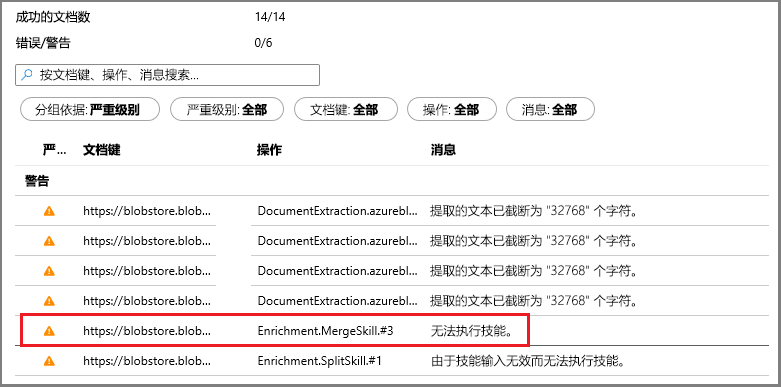
单击特定的状态行时将显示详细信息。 此警告表明合并在达到最大阈值(此特定 PDF 较大)后停止。

搜索浏览器中的查询
创建索引后,可以运行查询以返回结果。 为完成此任务,请在门户中使用 搜索浏览器。
- 在搜索服务仪表板页上,单击命令栏上的“搜索浏览器”。
- 选择顶部的“更改索引”,选择创建的索引。
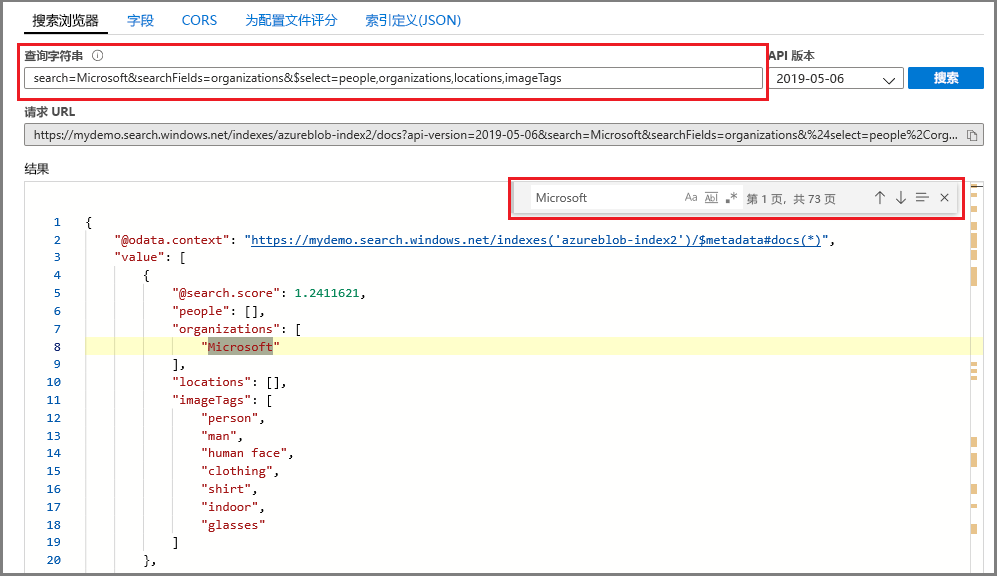
- 输入要在其中查询索引的搜索字符串,例如
search=Microsoft&$select=people,organizations,locations,imageTags。
随后会返回 JSON 格式的结果。这些结果可能非常冗长且难以阅读,尤其是出现在源自 Azure Blob 的大型文档中时。 在此工具中搜索时,可以借鉴一些提示,其中包括以下技术:
- 追加
$select,以指定要包含在结果中的字段。 - 使用 CTRL-F 在 JSON 中搜索特定属性或术语。
查询字符串区分大小写,因此如果收到“未知字段”消息,请检查“字段”或“索引定义(JSON)”以验证名称和大小写。