使用Azure Databricks Struct Stream存取Azure HDInsight Kafka
分类: Azure Databricks ◆ 标签: #Databricks #Spark ◆ 发布于: 2025-02-15 18:34:02

如果想要使用Azure Databricks Struct Stream存取Azure HDInsight Kafka,需要满足一些必要的条件:
Azure HDInsight不允许通过公网存取Kafka服务,客户端或者应用要存取这个服务,必须通过适当的途径连入Azure HDInsight的虚拟网络里。Azure HDInsight Kafka服务默认情况下不能通过IP地址访问,需要更改它的配置,使得该服务可以通过IP地址进行访问。
讨论一下实现这个目的的分步步骤:
创建一个Azure资源组,所有其他的资源都使用该资源管理。
创建一个虚拟网络。
创建一个
Azure Databricks服务。配置
Azure Databricks和之前创建的虚拟机网络的Peer网络关系。创建一个
Azure HDInsight, 并在创建的时候将这个Azure HDInsight集群链接到之前创建的虚拟网络中。通过
Ambari Portal更改Azure HDInsight Kafka的配置,使其可以用ip地址进行访问。创建
Kafka Topic在
Azure Databricks里创建一个基于Scala的Notebook, 通过Kafka Broker的IP地址进行访问
这些步骤里,步骤1, 步骤2,步骤3,这些步骤都没有什么技巧可言,使用Azure Portal, 可以一步一步的来完成,但是其他的一些步骤有一些需要注意的地方。
配置Azure Databricks和虚拟网络之间的Peer网络关系
这里需要注意的是看上去Azure Databricks有一个限制:只能支持在同一个区域的虚拟网络创建Peer的网络关系。
创建完成虚拟网络和Databricks集群之后,选择Databricks的资源,然后选择左侧菜单: Settings -> Virtual Network Peerings, 然后添加新的Peer:
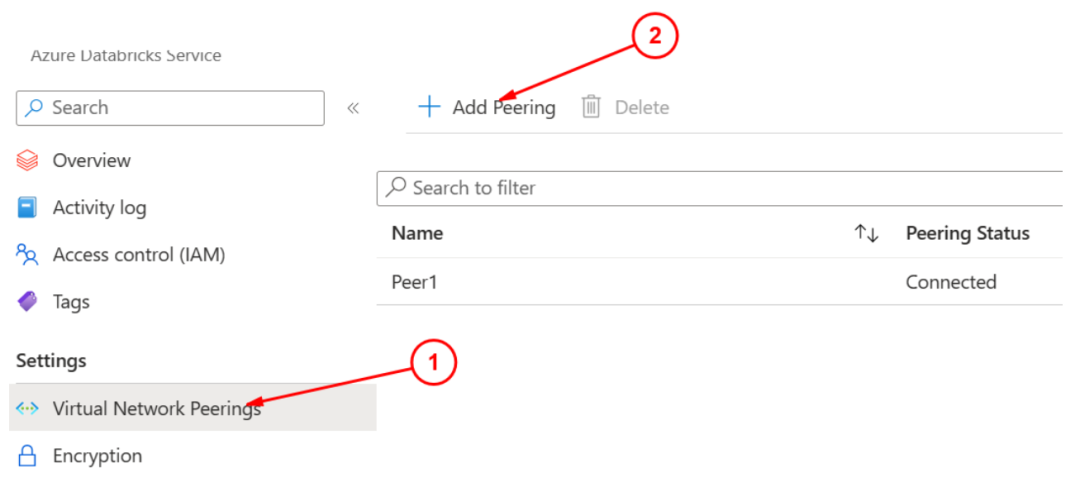
选择Add Peering之后,开始添加基本的信息:
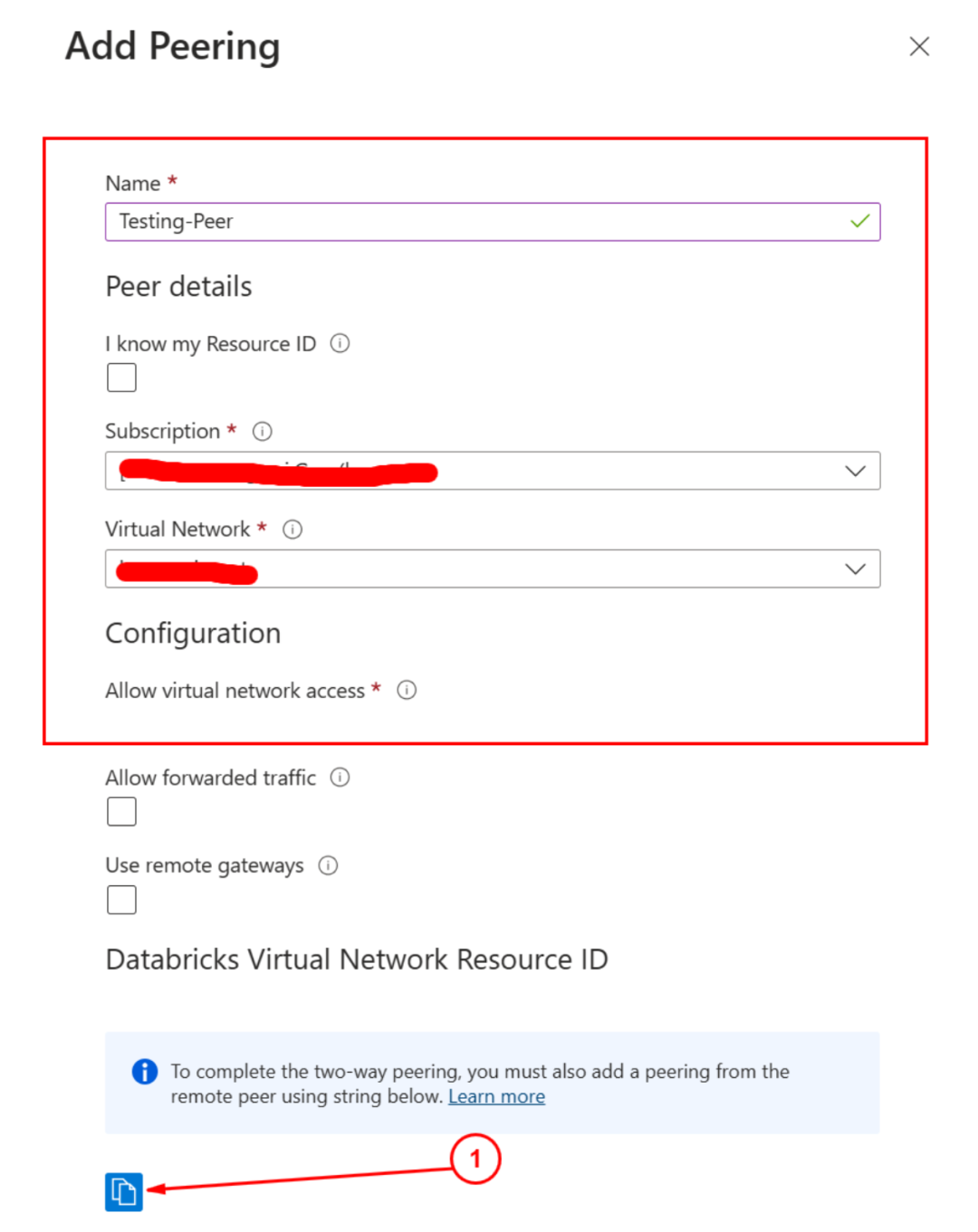
选择你的订阅和在同一个区域创建好的虚拟机网络,这里需要注意的是1处的Databricks Virtual Network Resource ID, 点击这里将该Resrouce ID拷贝下来,备用。
该界面保存之后,要注意的是Peer并没有结束,可以观察到该Peer的状态仍然还是处于初始化的状态,要继续完成网络Peer还需要在之前创建的虚拟网络上使用上面拷贝出来的resource ID在虚拟网络资源处再添加一次。
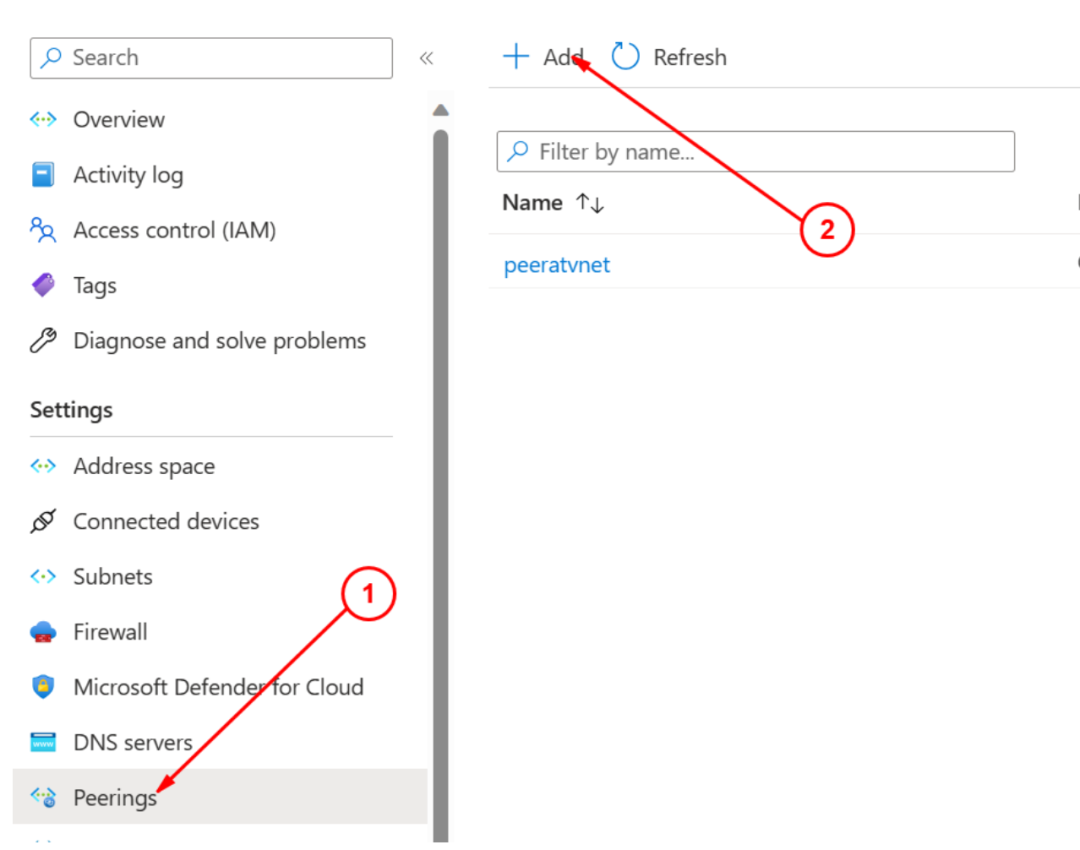
在虚拟网络上配置Peer
找到创建的虚拟网络资源之后,从左侧的菜单Settings -> Peerings, 添加一个新的Peer:
在添加的界面中Remote virtual network 里选择选项I know my resource ID, 值填上上一步在里备份的Databricks Virtual Network Resrouce ID就可以完成整个的配置了:
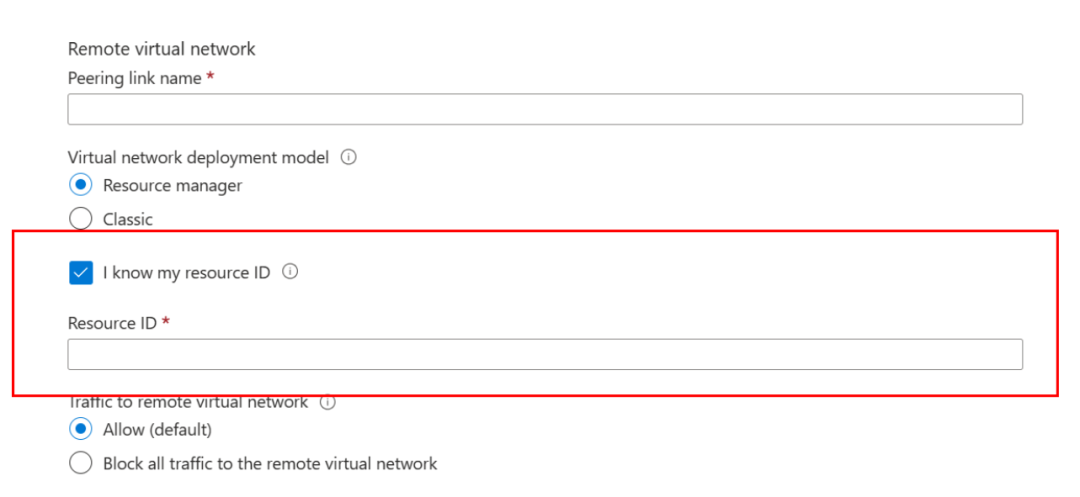
保存之后再分别在Databricks和虚拟网络两侧观察发现Peer的状态变为Conntected即表示正常配对成功。
配置Azure HDInsight使得Kafka支持IP地址访问
打开Ambari Portal, 然后左侧菜单Kafka, 然后选择配置,在配置里过滤kafka-env, 找到配置Kafka-env Template, 如下图:
在地下添加配置:
# Configure Kafka to advertise IP addresses instead of FQDN
IP_ADDRESS=$(hostname -i)
echo advertised.listeners=$IP_ADDRESS
sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties
echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.properties
保存配置,然后继续搜索配置listeners, 更改配置为:PLAINTEXT://0.0.0.0:9092, 该值默认为PLAINTEXT://localhost:9092, 如下图:

更改完成之后,记得先将集群设为维护模式,然后重启Kafka服务,Ambari也会提醒你需要重启。
经过这个更改即可以完成了Kafka监听IP地址了。
在Databricks上测试Struct Stream
经过以上步骤Dataricks已经可以直接访问到Azure HDInsight里的集群节点了,但是还需要注意的是由于Azure HDInsight集群里节点之间的通讯是通过域名访问,并且没有通过DNS进行解析,反而是直接使用/etc/hosts文件进行解析。因此在Databricks上只能通过ip地址进行访问
可以通过ssh登录到Azure HDInsight集群上通过该命令拿到zookeeper的具体机器名以及kafka borker的机器名:
curl -u admin:"<Your Password>" -G "https://<Your Cluster Name>.azurehdinsight.cn/api/v1/clusters/hongweikafka/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | jq -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")"
拿到zookeeper Server列表。
curl -u admin:"<Your Password>" -G "https://<Your Cluster>.azurehdinsight.cn/api/v1/clusters/hongweikafka/services/KAFKA/components/KAFKA_BROKER" |jq -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"
针对于Databricks,我们需要Kafka broker的服务IP地址,可以通过在HDInsight集群上cat /etc/hosts得到所有的ip地址。
然后您可以通过如下的代码尝试访问Kafka了。
val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json"
val result = scala.io.Source.fromURL(url).mkString
// Create a dataframe from the JSON data
val taxiDF = spark.read.json(Seq(result).toDS)
// Display the dataframe containing trip data
taxiDF.show()
val kafkaBrokers="10.3.0.11:9092,10.3.0.14:9092,10.3.0.12:9092,10.3.0.13:9092"
val kafkaTopic="tripdata"
println("Finished setting Kafka broker and topic configuration.")
// Select the vendorid as the key and save the JSON string as the value.
val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save()
println("Data sent to Kafka")
import org.apache.spark.sql._
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
// Define a schema for the data
val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType)
println("Schema declared")
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load()
// Select data and write to file
val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save()
println("Wrote data to file")
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000)
println("Wrote data to file")
至此就可以顺利的通过Spark Struct Stream访问Kafka了。